1. Introduction
My research centers around how market participants act upon their perceived informational advantages over others. And because of this, I have always found it intriguing to leverage people’s digital traffic in accessing firms’ EDGAR filings to capture the dynamics of market participants’ information sets. During my explorations, I found IPinfo.io generously provided all the registered users with the bulk data for organization to which the IP address is registered. Per their invitation, I am pleased to share my methods on distinguishing EDGAR downloads from different stakeholder groups, especially those from the retail and institutional investors.
In this blog post, I will firstly introduce some background information about EDGAR and EDGAR logs in case some readers are not familiar about these terms. Then I showcase the potential of the EDGAR log files in capturing the intended moves from different stakeholder groups. Readers with related backgrounds can skip these two sections. Next, I discuss the two viable pathways of figuring out the stakeholder types of EDGAR downloads and outlines the reason why I choose the pathway I utilize in this blog.
Regarding the technical roadmap of the pathway chosen, I will begin by compiling a list of stakeholders with potentially informative EDGAR downloads. Next, I will demonstrate the process of searching for their respective IP address ranges. By combining the IP ranges with the EDGAR logs, I will proceed to extract the downloads from the targeted stakeholders. Finally, I will illustrate how to expand the stakeholder list and repeat the previous procedures to capture the EDGAR downloads for an entire stakeholder category, such as institutional investors and retail investors.
In the conclusion part, I will focus on discussing avenues for researchers and practitioners to continue deriving valuable insights from EDGAR logs when considering the cessation of SEC’s disclosure of EDGAR logs in the past few years and the increased redaction in the recently updated EDGAR logs.
2. What is EDGAR and EDGAR Log?
EDGAR (Electronic Data Gathering, Analysis, and Retrieval) is an online database maintained by the U.S. Securities and Exchange Commission (SEC). It collects and stores financial and non-financial information filed by publicly traded companies and other entities. Some common filings made through EDGAR include annual reports (Form 10-K), quarterly reports (Form 10-Q), and other specialized forms like proxy statements (Form DEF 14A) and registration statements for new securities offerings (Form S-1). The database provides public access to essential financial and operational information about these companies, aiding stakeholders in their research and analysis on firms.
EDGAR log files provide information on internet search traffic for EDGAR filings through SEC.gov. Whenever users access the EDGAR database to retrieve or submit documents, the logs record various details about those interactions. These logs typically include information such as:
- IP addresses: The unique numerical addresses assigned to each device accessing EDGAR.
- Timestamps: The date and time of each interaction or request.
- Pages visited: Details of the specific pages or documents accessed on the EDGAR website.
- User agent: Information about the web browser or software used to access EDGAR.
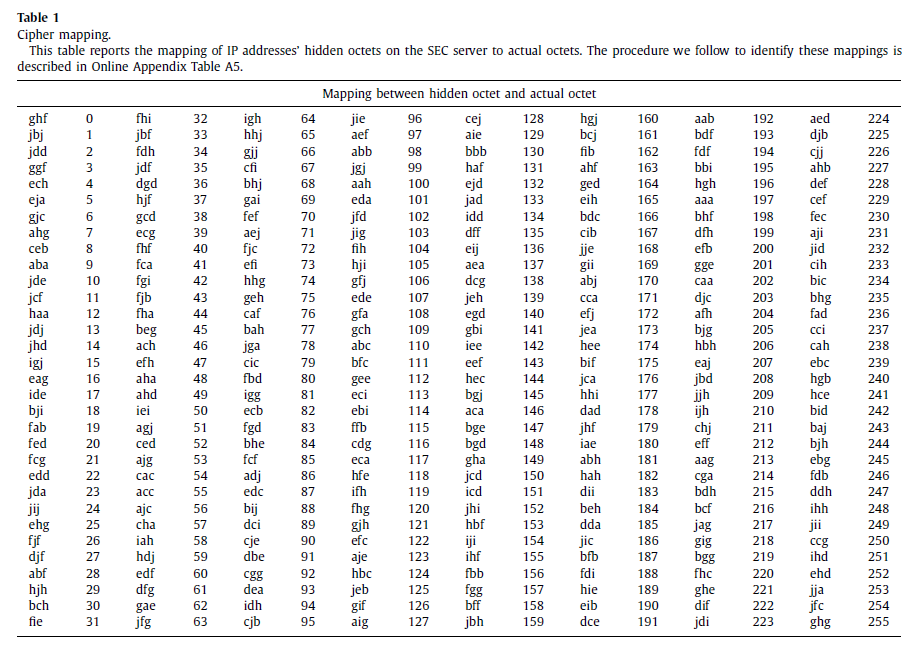
To provide readers with a glimpse of the EDGAR log files, I present five lines extracted from the EDGAR log for Sep. 30, 2013. The variable definitions for these files are sourced from the SEC and can be accessed at this link. Although the fourth octets of the IP addresses are redacted, their precise retrieval is feasible using the map provided by Chen et al. (2020, JFE). I will discuss this issue further in the Section 5.
| ip | date | time | zone | cik | accession | extention | code | size | idx | norefer | noagent | find | crawler | browser |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 200.193.144.ede | 9/30/2013 | 14:30:43 | 0 | 1534731 | 0001534731-13-000003 | 9.04.htm | 200 | 18289 | 0 | 0 | 1 | 7 | 0 | |
| 76.127.169.chj | 9/30/2013 | 14:40:58 | 0 | 1070524 | 0001070524-13-000029 | gcbc-20130930xdef14a.htm | 200 | 51316 | 0 | 0 | 1 | 9 | 0 | |
| 50.201.183.abb | 9/30/2013 | 14:42:31 | 0 | 1237746 | 0001193125-13-361255 | =-index.htm | 200 | 3178 | 1 | 0 | 1 | 1 | 0 | |
| 50.201.183.abb | 9/30/2013 | 14:42:32 | 0 | 1237746 | 0001193125-13-361255 | d555515ds1.htm | 304 | 285 | 0 | 0 | 1 | 9 | 0 | |
| 209.23.223.ech | 9/30/2013 | 14:42:47 | 0 | 1063254 | 0001171843-11-003356 | =-index.htm | 200 | 2378 | 1 | 0 | 1 | 1 | 0 |
3. The Potential of EDGAR Logs
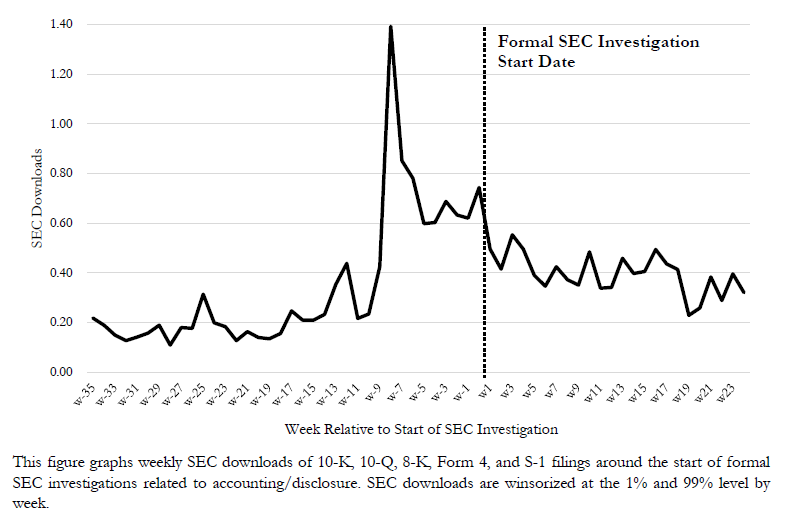
While the EDGAR logs attracted my attention for the relevance in revealing investor’ trading intention (e.g., Drake et al., 2020 TAR), I found their potential is far beyond that. One fascinating usage comes from Holzman et al. (2023, JAE). In this paper, the authors graphed weekly SEC downloads of firms’ 10-K, 10-Q, 8-K, Form 4, and S-1 filings around the start of its formal investigations on the pertained firms, as shown in Figure 1. Apparently, there is a noticeable spike in SEC downloads approximately 60 days prior to the formal SEC investigation start date, which could serve as a powerful signal for firms’ risk of being investigated if the EDGAR logs were updated in time. Having access to this signal with latency short enough could yield substantial profits, as firms are not obliged to disclose ongoing investigations, yet these investigations are highly predictive of significant price declines for the involved companies (Blackburne et al., 2021 MS).
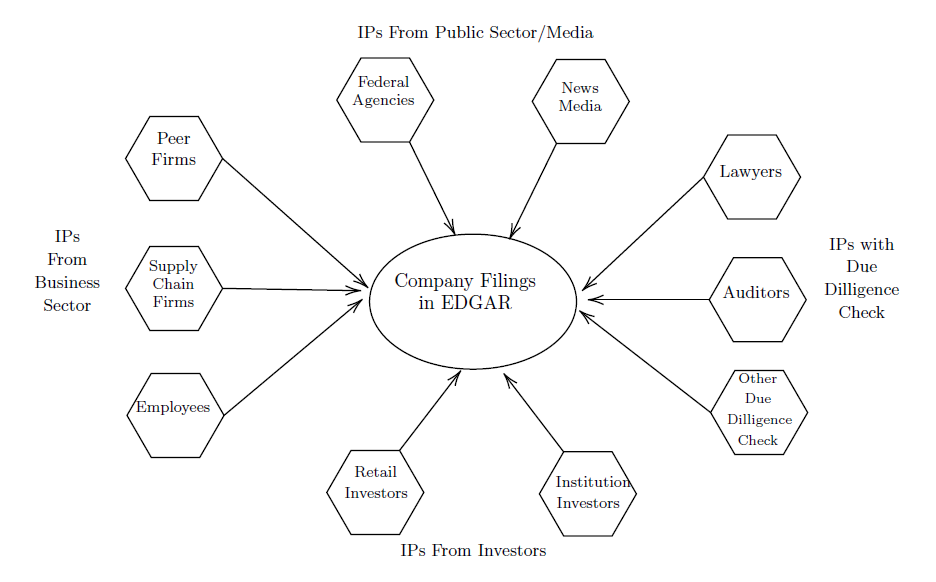
The extant literature suggests that a wide spectrum of stakeholders actively engages in downloading company filings through EDGAR and none of these information acquisition activities come from the vacuum. Notably, investors refer to these filings to validate their private information, thereby making EDGAR downloads from investors indicative of firms’ subsequent abnormal returns (Drake et al., 2020 TAR, Crane et al., 2023 MS). Financial intermediaries (e.g., equity analysts) who extensively access company filings demonstrate higher dedication and efforts and are more likely to issue more precise forecasts compared to their peers (Gibbons et al., 2021 MS). Firms’ peers and competitors access company filings to inform their own investment and production decisions (Bernard et al., 2020 JFE). Imitators (copycats) can indeed profit from emulating their peer companies’ strategies (Cao et al., 2021 JAR). Potential and incumbent employees also utilize company filings to make informed career decisions. Firms exhibiting remarkable earnings growth attract more job seekers, whose rational behavior is supported by financial information’s predictive value for future job prospects, including job openings and career growth (Choi et al., 2023 JAE). The SEC is not the sole federal agency utilizing EDGAR. The tax regulator IRS (Internal Revenue Service) and the economic policy maker Federal Reserve (the Fed) systematically leverage EDGAR to facilitate their respective duties (Bozanic et al., 2017 JAR; Li et al., 2023 TAR). Due diligence agencies like auditors access the financial statements of nonclient firms for benchmarking, indicating a need to clarify their client’s financial records (Drake et al., 2019 RAST).
In addition to the stakeholders whose informative EDGAR downloads have been well-documented in the existing literature, Figure 2 illustrates the broader potential of EDGAR log files. Beyond investors, financial intermediaries, peers, employees, and auditors, other relevant stakeholders also have demands in accessing company filings. These include supplier and customer firms, law firms, due diligence investigators, news media, and so on.
For instance, a Wall Street Journal article published on June 29, 2022, highlights how news reporters analyzed 169,000 Form 144 filings submitted by company insiders from 2016 through 2021. The article accused managers in several firms, such as Plug Power Inc., Nektar Therapeutics, Aemetis, etc., of unfaithfully leveraging automatic trading plans (10b5-1 plans) to realize de facto insider trading profits. Imagine firms have a sense of Wall Street Journal’s abnormal searches on them, what a blessing it would be for their PR departments (I am not suggesting such practice is valid or encouraging it anyway).
Overall, the information acquisition traffic captured in the EDGAR logs holds significant potential. I am convinced that there are further valuable insights to be discovered with these logs.
4. Determine Pathway to Classify EDGAR Downloads
Regarding the classification process for EDGAR downloads, there are two viable approaches to consider.
The first option involves gathering unique IP addresses from the EDGAR log files, identifying the organizations associated with each IP address, and subsequently classifying the type of organizations and their corresponding downloads based on this organizational information.
The second option starts with a specified entity list belonging to a designated stakeholder group. Next, you identify the IP addresses of the entities of interest using the WHOIS or other tools. Then, you select the downloads from EDGAR logs with IP addresses falling within the entities’ IP ranges. Consequently, these selected downloads by definition belong to the specified stakeholder group.
In my perspective, the second pathway offers superior flexibility and higher data processing efficiency. To elaborate, in the first pathway, determining the organization of each download can lead to a significant number of inefficient data requests. In contrast, the second option is more entity-oriented, allowing for the identification of downloads solely from a small number of specific entities without figuring out the organization of every single download. At the same time, the second pathway also allows for the possibility of expanding the list of entities to encompass the entire group of certain stakeholders. These features make the second pathway a more favorable choice for determining the stakeholder group of EDGAR users, and I will follow this approach in this blog.

5. Locate EDGAR downloads From Specified Stakeholders
In this section, I will demonstrate the process of locating EDGAR downloads from a specified list of stakeholders. Once mastered, this method will enable us to capture EDGAR downloads from any stakeholder group of interest simply by expanding our stakeholder list accordingly.
Step 1: Compile the Stakeholder List
To ensure comprehensive coverage of stakeholder spectrums, my stakeholder list in the following table includes as many categories as possible. Unlike other stakeholder groups, categorizing retail investors is less straightforward. Following the approach of Drake et al. (2020, TAR), I consider the retail investor group to consist of EDGAR users accessing the system through one of the top ten U.S. or top ten worldwide internet service providers (ISP), such as Comcast or Time Warner.
| Name | Category |
|---|---|
| Wells Fargo | Top Institutional Investors |
| Goldman Sachs | Top Institutional Investors |
| Verizon Online LLC | Top Internet Service Providers (Retailers) |
| Comcast Cable Communications | Top Internet Service Providers (Retailers) |
| Securities and Exchange Commission | Government Agencies |
| Internal Revenue Service | Government Agencies |
| Tesla Inc. | Company |
| Nvidia Corporation | Company |
| The New York Times | Media |
| The Wall Street Journal | Media |
| Kirkland & Ellis | Law Firm |
| Latham & Watkins | Law Firm |
| Ernst & Young | Audit Firm |
| KPMG | Audit Firm |
| Probes Reporter | Due Diligence Check |
| Check Fund Manager | Due Diligence Check |
Step 2: Google the IP Addresses of Stakeholders
From my reading of extant literature, researchers typically employ a ‘‘WhoIs’’ Perl script to build a database based on the American Registry of Internet Numbers (ARIN; see: https://www.arin.net/) to identify the organization to which the IP address is registered (e.g., Drake, 2020 TAR). However, I bypassed this step as IPinfo.io generously provides a highly similar dataset free of charge, available for download by any registered user at this link. The key distinction lies in the identifiers used for organizations: IPinfo.io’s dataset utilizes Autonomous System Numbers (ASNs), whereas the dataset built on WhoIs relies on ARIN as the identifier. Either case, the organization name and the IP address ranges can be mapped with the identifier.

I present the first five rows of this dataset to showcase how does this dataset look like.
| start_ip | end_ip | asn | name | domain |
|---|---|---|---|---|
| 1.0.0.0 | 1.0.0.255 | AS13335 | Cloudflare, Inc. | cloudflare.com |
| 1.0.4.0 | 1.0.7.255 | AS38803 | Wirefreebroadband Pty Ltd | gtelecom.com.au |
| 1.0.16.0 | 1.0.16.255 | AS2519 | ARTERIA Networks Corporation | arteria-net.com |
| 1.0.32.0 | 1.0.32.255 | AS141748 | QUANTUM DATA COMMUNICATIONS, INC. | qdatacom.com |
| 1.0.64.0 | 1.0.127.255 | AS18144 | Energia Communications,Inc. | enecom.co.jp |
Having IPinfo’s ASN dataset in hand, I conduct Google searches for each entity’s name along with “IPinfo” and record the corresponding ASNs from the search results. These ASNs will serve as the key to merge with IPinfo’s ASN dataset, allowing us to identify the IP address ranges of the entities of interest.
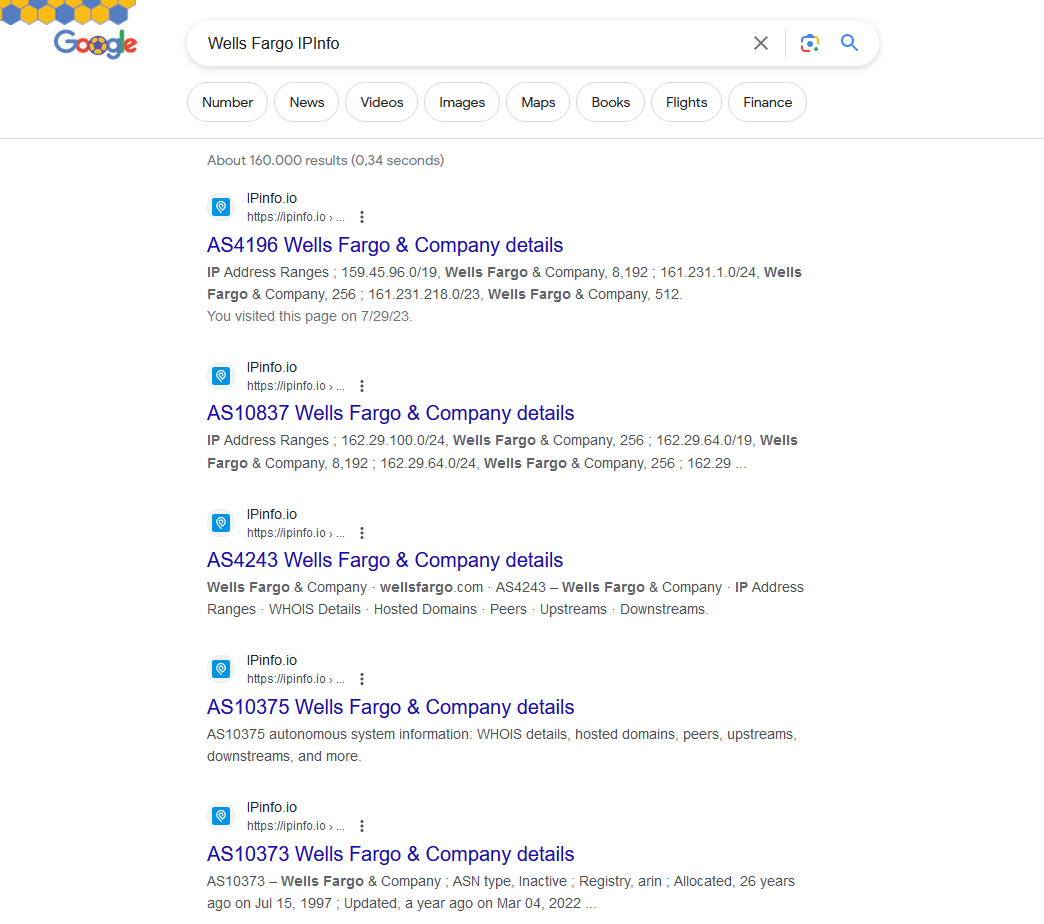
Using the institutional investor “Wells Fargo” as an illustration, Figure 4 showcases the retrieved results for Googling “Wells Fargo IPinfo.” What I did was to collect headlines from all the search results, specifically retaining those containing ASN-formatted characters while ensuring inclusion of the first word of the institution, “Wells,” in the headline. Then I extract all the unique ASN numbers of retained search results. In this case, I would record AS4196, AS10837, AS4243, AS10375, and AS10373. I proceed to repeat this process for all stakeholders in the list, thereby obtaining the respective ASN numbers for each of them.
While manually Googling a short list of stakeholders is viable, our objective is to acquire EDGAR downloads from the whole group of institutional/retail investors and other stakeholders. This will inevitably result in a substantial list, making it imperative to automate the process of Google searches for ASN numbers.
To automate these Google searches, I slightly modified the codes I introduced in Utilize Google Search as an Integrated Data Source. Readers can check there for further technical details on how to automate the Google searches. The codes for automating the ASN searches in this blog are as follows.
|
|
The output of this procedures is as follows. With the ASN numbers in the first column, we are ready to merge it with the ASN dataset for locating the organization’s IP ranges.
| asn | webname | searchkey | category |
|---|---|---|---|
| AS4196 | AS4196 Wells Fargo & Company details | Wells Fargo | Top Institutional Investors |
| AS10837 | AS10837 Wells Fargo & Company details | Wells Fargo | Top Institutional Investors |
| … | |||
| AS205483 | AS205483 KPMG S.A details | KPMG | Audit Firm |
| AS134036 | AS134036 KPMG Global Services Private Limited details | KPMG | Audit Firm |
| AS204299 | AS204299 KPMG Audit S.a r.l. details | KPMG | Audit Firm |
I then merge the ASNs of stakeholders with the IPinfo.io’s ASN dataset to acquire their respective IP addresses. For the ease of the subsequent merge with EDGAR log files, I opt to utilize SAS for this procedure. The codes are as follows.
|
|
The output of this step is the IP addresses of the stakeholders of interest.
| asn | searchkey | category | start_ip | end_ip | name | domain |
|---|---|---|---|---|---|---|
| AS10372 | Wells Fargo | Top Institutional Investors | 159.37.112.0 | 159.37.115.255 | Wells Fargo & Company | wellsfargo.com |
| AS10372 | Wells Fargo | Top Institutional Investors | 159.37.120.0 | 159.37.123.255 | Wells Fargo & Company | wellsfargo.com |
| AS10837 | Wells Fargo | Top Institutional Investors | 151.151.0.0 | 151.151.127.255 | Wells Fargo & Company | wellsfargo.com |
| … |
Step 2.5: What If Google Searches Do Not Work?
It’s worth noted that it’s possible that you do not have any valid ASNs returned for some of your Google searches. In such as case, please remember that Google search is just one among many ways to locate firms’ IP address with their names. There are two alternative ways that I would recommend when the Google search does not work.
-
Perform a fuzzy match of your stakeholder’s name with the corresponding Name entries in the ASN database provided by IPinfo.com.
-
Conduct a Google search for the stakeholder’s domain and then use websites such as whatismyip.com, experte.com, or any other DNS lookup tool to retrieve the IP address associated with the domain. For example, with the domain of the Wall Street Journal
https://wsj.com, the IP addresses are returned as in Figure 5.
Figure 6: Obtain IP Address with Domain
By any means, our task is not Google search per se but to locate stakeholders’ IP addresses based on their names. Only we have successfully determined the IP addresses associated with a specific stakeholder can we proceed to locate EDGAR downloads from them.
Step 3: Locate EDGAR Downloads from Specified Stakeholders
Having obtained the IP addresses of each stakeholder, our next step is to merge them with the EDGAR logs to identify downloads originating from these stakeholders. To facilitate this process, it is essential to prepare the mapping files provided by Chen et al. (2020, JFE) beforehand, which will enable us to replace the redacted fourth octets in EDGAR logs with the precise ones.
The SAS codes for this step are as follows. First, I import the EDGAR log file and the mapping file into the SAS. Then, I extract the concealed fourth octets from each line in the log file and use them as the key variable for merging with the mapping file. This procedure enables the determination of the accurate fourth octets for each IP address in the log file. Finally, I merge the precise IP addresses in log file with the IP ranges of stakeholders to identify the EDGAR downloads from the specified stakeholders.
|
|
The output of this procedure is as follows. Note that all these prior procedures are only based on the EDGAR log file for a single day. You can implement them log by log to capture the time series of stakeholders’ information acquisition interests.
| ip | date | time | zone | cik | char | num | exactip | name | asn | domain |
|---|---|---|---|---|---|---|---|---|---|---|
| 162.138.210.ggf | 6/30/2017 | 01JAN60:00:00:02 | 0 | 1295391 | ggf | 3 | 162.138.210.3 | U.S. Securities & Exchange Commission | AS26229 | sec.gov |
| 162.138.210.ggf | 6/30/2017 | 01JAN60:00:00:14 | 0 | 314808 | ggf | 3 | 162.138.210.3 | U.S. Securities & Exchange Commission | AS26229 | sec.gov |
| 162.138.210.ggf | 6/30/2017 | 01JAN60:00:00:15 | 0 | 314808 | ggf | 3 | 162.138.210.3 | U.S. Securities & Exchange Commission | AS26229 | sec.gov |
| … | ||||||||||
| 204.4.182.ide | 6/30/2017 | 01JAN60:00:40:12 | 0 | 850209 | ide | 17 | 204.4.182.17 | The Goldman Sachs Group, Inc. | AS33598 | gs.com |
| 204.4.182.jhd | 6/30/2017 | 01JAN60:00:26:27 | 0 | 1559992 | jhd | 14 | 204.4.182.14 | The Goldman Sachs Group, Inc. | AS33598 | gs.com |
| 204.4.182.jhd | 6/30/2017 | 01JAN60:00:30:07 | 0 | 1657939 | jhd | 14 | 204.4.182.14 | The Goldman Sachs Group, Inc. | AS33598 | gs.com |
6. Locate the EDGAR Downloads From Specified Stakeholder Group
At this stage, we have successfully extracted all the EDGAR downloads from a given stakeholder list for a specific day. By expanding the stakeholder list properly, we can capture the EDGAR downloads from specified stakeholder groups.
Locate EDGAR Downloads from Retail Investors
I adopt the methodology employed by Drake et al. (2020, TAR) to identify EDGAR downloads from retail investors. In particular, the retail investor group is defined as EDGAR users accessing the system via one of the top ten U.S. or top ten worldwide internet service providers (ISP), such as Comcast or Time Warner. The following table provides the list of top ten U.S. internet service providers (ISP) provided by Drake et al. (2020, TAR) in Appendix A.
| Name | Category |
|---|---|
| Time Warner Cable Internet LLC | Top Internet Service Providers (Retailers) |
| Verizon Online LLC | Top Internet Service Providers (Retailers) |
| Comcast Cable Communications, Inc. | Top Internet Service Providers (Retailers) |
| Cox Communications | Top Internet Service Providers (Retailers) |
| EarthLink, Inc. | Top Internet Service Providers (Retailers) |
| AT&T Internet Services | Top Internet Service Providers (Retailers) |
| Qwest Communications Company | Top Internet Service Providers (Retailers) |
| Charter Communications | Top Internet Service Providers (Retailers) |
| Hurricane Electric | Top Internet Service Providers (Retailers) |
| Optimum Online | Top Internet Service Providers (Retailers) |
Using the provided list of top 10 internet service providers worldwide, you can replicate the procedures outlined in Section 5 to identify all the EDGAR downloads from retail investors within a given log file. There are two tips to improve the program efficiency here.
-
As which internet service providers (ISPs) the retailers are using is not of primary importance in this context, you could avoid distinguishing among different ISPs.
-
Given that internet service providers (ISPs) commonly utilize a broad range of overlapping IP addresses, merging the overlapping IP ranges to reduce the number of IP ranges needed to be fit for EDGAR logs will also significantly enhance the program efficiency. As an illustrative example, consider the table below, which presents two IP ranges associated with Verizon. Without merging these IP ranges, the process would require checking EDGAR downloads against each IP range individually, totaling two separate checks. However, by identifying the joint
start_ipandend_ipof these two ranges and merging them, we can effectively consolidate the IP ranges and reduce the EDGAR download check to just one instance. This streamlining significantly improves the efficiency of the program.asn searchkey category start_ip end_ip name AS2828 Verizon Online LLC TOP Internet Service Providers (Retailers) 140.239.0.0 140.239.75.255 Verizon Business AS2828 Verizon Online LLC TOP Internet Service Providers (Retailers) 140.239.144.0 140.239.233.255 Verizon Business
Locate EDGAR Downloads from Institutional Investors
The specification of the list of institutional investors is contingent upon the specific requirements and objectives of researchers or practitioners as this category encompasses a diverse range of entities, such as investment banks, hedge funds, commercial banks, insurance companies, among others. Using the methods elucidated in this blog, researchers and practitioners have the flexibility to compile a separate list of the most prominent entities from each subgroup and then combine them to form the whole institutional group.
Suppose you are interested in studying EDGAR downloads of hedge funds, as Crane et al. (2023, MS) did. There are multiple avenues to obtain a list of institutional investors. For instance, a quick online search using keywords like ‘Top 100 hedge funds in US’ can lead you to resources such as the List of Top 100 Hedge Fund Managers by Managed AUM provided by the Sovereign Wealth Fund Institute. Alternatively, you could access the archival dataset from WRDS Thomson Reuters Institutional (13f) Holdings or Corporate Ownership of S&P 500 firms for a more comprehensive list of institutional investors, which includes hedge funds.
Regardless of the sources chosen, you always have the discretion to compile a list of entities belonging to the institutional investor group, and then utilize the techniques introduced in Section 5 to locate the EDGAR downloads from them.
7. Summary
In this blog, I have explored the potential and methodologies for determining the stakeholder group of EDGAR users. However, it is essential to acknowledge that the SEC ceased updating EDGAR log files after June 30, 2017 for several years. While there were recent updates to the log files between May 19, 2020, and Feb 13, 2022, these new log files no longer include IP addresses, which deters identifying the identity of EDGAR users.
Technically, one can make a Freedom of Information Act (FOIA) request to the SEC for unredacted EDGAR logs, as permitted by the Freedom of Information Act enacted in 1967. However, it is important to note that even before 2017, the SEC disclosed the EDGAR log files with a considerable latency of about one year. This delay could render much of the information embedded in EDGAR downloads stale, limiting their practical utility for trading purposes.
Despite these complexities, it is undeniable that EDGAR logs still offer a valuable playing field for practitioners to gain retrospective insights. And I believe they will continue to provide a rich source of information for researchers to study market dynamics.
Easter Eggs
Thanks for reading all over through! As a big fan of Christopher Nolan, I just watched the Oppenheimer in the movie theater. The movie was magnificent and made feel my efforts in sparing out 3 hours to watch it during my super busy job market preparation season was not wasted. But I have to say it might be hard to delve in if you do not have a decent understanding of the context before watching the movie - I did not see significant efforts from Nolan in this regard and saw some people in the theater left in the middle.

Combining my personal homework and movie-watching experience, I will share five things you may want to know before watching Oppenheimer. Most of them are from the wiki profile of J. Robert Oppenheimer, and I highlight them as they are clues for following the story line of the movie.
- The overarching context of this movie: J. Robert Oppenheimer directed the Los Alamos Laboratory during World War II, designing nuclear bombs. Given the Nazis has made progress in developing this weapon (see the Einstein–Szilard letter in 1939), the race against the Nazis had a crucial impact on the future of human lives.
- In 1924, while studying empirical physics in Cambridge, Oppenheimer expressed unhappiness. He even left a poisoned apple on his tutor Blackett’s desk, which went uneaten. In 1926, he moved to the University of Göttingen to study under Max Born, where he began his influential career in theoretical physics at this leading center for this field then. In the autumn of 1928, Oppenheimer visited Paul Ehrenfest’s institute at the University of Leiden, the Netherlands, where he impressed by giving lectures in Dutch, despite having little experience with the language.
- On returning to the United States, Oppenheimer accepted an associate professorship from the University of California, Berkeley. During his lecturing time there, Oppenheimer had associations with individuals who were members of or sympathetic to the Communist Party and was part of intellectual circles at Berkeley that included left-leaning academics, writers, and activists. His lover Jean Tatlock (started from 1936 and ended in 1939), wife Katherine (“Kitty”) Puening (since 1940), brother Frank, and Frank’s wife Jackie were all (once) active in the Communist Party in the 1930s or 1940s. Moreover, one of his close friends during the weapon development was accused to leak the confidential information to the Soviet Union. These led to suspicions about his loyalty to the United States during the McCarthy era in 1950s and the revocation of his security clearance following a 1954 security hearing.
- Oppenheimer struggled a lot from the moral question about weapons of mass destruction. He later recalled that, while witnessing the explosion of the test bomb, Trinity, in July 1945, he thought of a verse from the Hindu holy book, the Bhagavad Gita: “If the radiance of a thousand suns were to burst at once into the sky, that would be like the splendor of the mighty one …” and “Now I am become Death, the destroyer of worlds.’ I suppose we all thought that, one way or another.” In October 1945, Oppenheimer met then US president Harry S. Truman and said he felt he had “blood on my hands”. These struggles also played a role in his strong opposition to the development of the hydrogen bomb, which hurt him during the McCarthy era.
- In 1947, Oppenheimer accepted an offer from Lewis Strauss to serve as a member of the Board of Consultants to Atomic Energy Commission. Lewis Strauss later became Oppenheimer’s biggest enemy and initiated the revocation of the latter’s security clearance in 1954. The anger between Lewis Strauss and Oppenheimer can be traced back to a public hearing in 1947, where Strauss had been questioned over security concerns regarding the exportation of radioactive isotopes, which he’d advocated for. Oppenheimer then not only disagreed with Strauss’ position but outright mocked it in front of everyone in attendance, which proved to be an important, bitter seed in his efforts to dismantle his career and reputation. Moreover, racked by guilt in the wake of Hiroshima and Nagasaki, Oppenheimer was strongly against the development of more destructive hydrogen bombs in post-war, whereas Strauss was on the opposite side. The latter suggested that if they do not develop hydrogen bombs first, their enemies would, and in turn they have to develop them anyway.
References
- Drake, Michael S., Bret A. Johnson, Darren T. Roulstone, and Jacob R. Thornock. “Is there information content in information acquisition?.” The Accounting Review 95, no. 2 (2020): 113-139.
- Chen, Huaizhi, Lauren Cohen, Umit Gurun, Dong Lou, and Christopher Malloy. “IQ from IP: Simplifying search in portfolio choice.” Journal of Financial Economics 138, no. 1 (2020): 118-137.
- Holzman, Eric R., Nathan T. Marshall, and Brent A. Schmidt. “When are firms on the hot seat? An analysis of SEC investigation preferences.” Journal of Accounting and Economics (2023): 101610.
- Blackburne, Terrence, John D. Kepler, Phillip J. Quinn, and Daniel Taylor. “Undisclosed SEC investigations.” Management Science 67, no. 6 (2021): 3403-3418.
- Crane, Alan, Kevin Crotty, and Tarik Umar. “Hedge funds and public information acquisition.” Management Science 69, no. 6 (2023): 3241-3262.
- Gibbons, Brian, Peter Iliev, and Jonathan Kalodimos. “Analyst information acquisition via EDGAR.” Management Science 67, no. 2 (2021): 769-793.
- Bernard, Darren, Terrence Blackburne, and Jacob Thornock. “Information flows among rivals and corporate investment.” Journal of Financial Economics 136, no. 3 (2020): 760-779.
- Cao, Sean Shun, Kai Du, Baozhong Yang, and Alan L. Zhang. “Copycat skills and disclosure costs: Evidence from peer companies’ digital footprints.” Journal of Accounting Research 59, no. 4 (2021): 1261-1302.
- Choi, Bong-Geun, Jung Ho Choi, and Sara Malik. “Not just for investors: The role of earnings announcements in guiding job seekers.” Journal of Accounting and Economics (2023): 101588.
- Bozanic, Zahn, Jeffrey L. Hoopes, Jacob R. Thornock, and Braden M. Williams. “IRS attention.” Journal of Accounting Research 55, no. 1 (2017): 79-114.
- Li, Edward X., Gary Lind, K. Ramesh, and Min Shen. “Externalities of accounting disclosures: evidence from the Federal Reserve.” The Accounting Review (2023): 1-27.
- Drake, Michael S., Phillip T. Lamoreaux, Phillip J. Quinn, and Jacob R. Thornock. “Auditor benchmarking of client disclosures.” Review of Accounting Studies 24 (2019): 393-425.
- McGinty, Tom, Maremont, Mark, “CEO Stock Sales Raise Questions About Insider Trading.” The Wall Street Journal (2022).