Motivation
In January 2021, a group of retail investors noticed that several hedge funds had taken large short positions on GameStop’s stock, essentially betting that its price would decline. Retail investors, many of whom were part of the Reddit community Wall Street Bets (hereafter, WSB), saw an opportunity to drive up the stock’s price and squeeze the short sellers. They began buying GameStop shares en masse, causing the stock price to skyrocket. Noticeably, according to a Wall Street Journal article published on Jan. 29, 2019, many online investors say advocacy from Keith Gill, a 34-year-old marketing professional and Chartered Financial Analyst (CFA) known by the Reddit username DeepFuckingValue, “helped turn them into a force powerful enough”.
My take-away from the GameStop frenzy is that a few sophisticated individuals in trading forums like WSB (e.g., Keith Gill in this case) can efficiently organize retailers (though not necessarily intentionally), and these organized retail investors could potentially gain significant market-moving power.
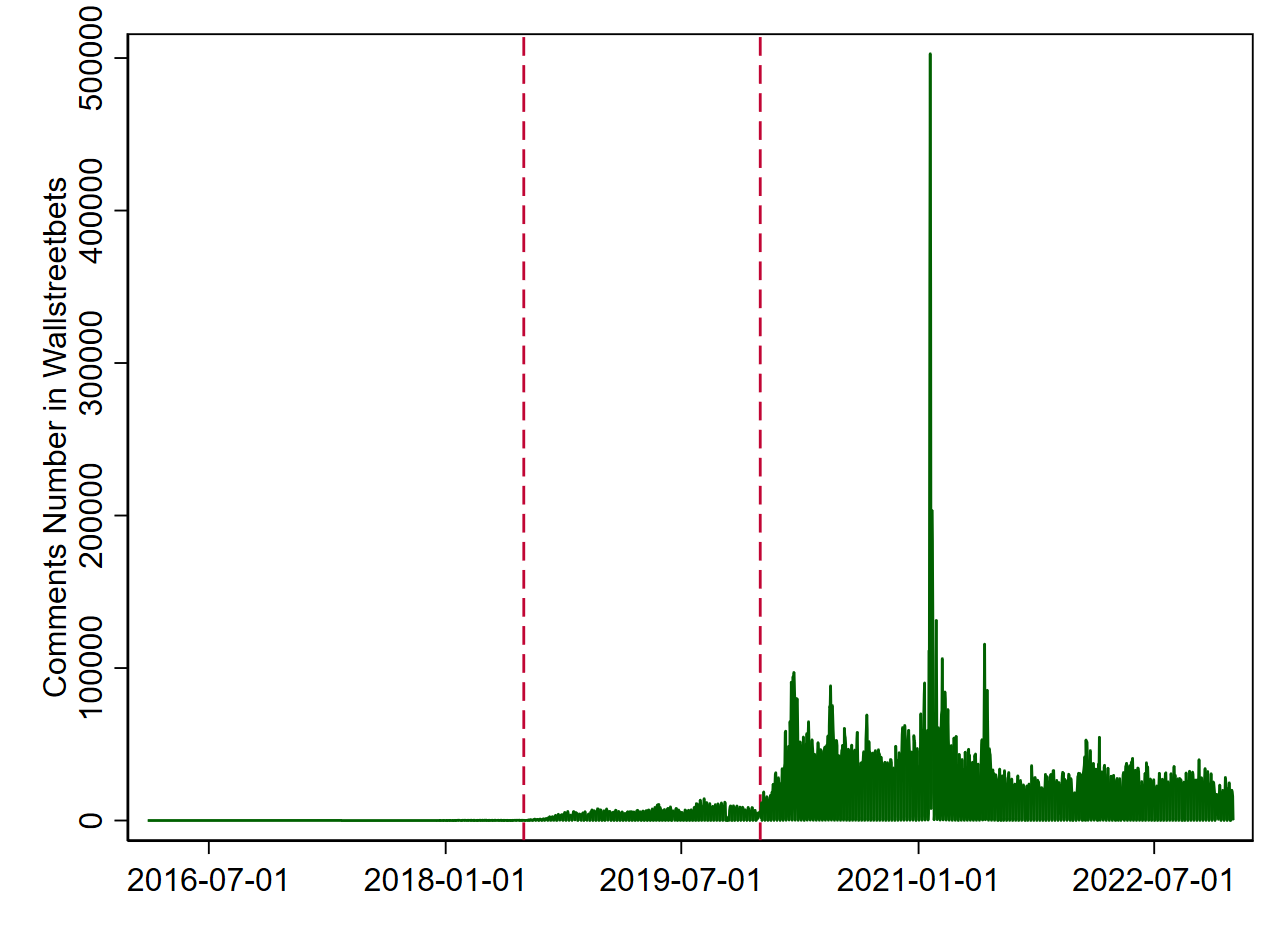
These patterns make analyzing WSB discussions (and also other trading forums) meaningful enough. The user booming after Gamestop frenzy makes it even more appealing. An immediate application would be to figure out what the potentially market-moving investor group, most of which are armchair investors, is discussing there, and optimize your own trading strategy upon it. For example, some hedge funds earned millions by mimicking the bet made by the Reddit renegades in Gamestop frenzy (Jakab, 2022 WSJ). The logic is old but simple: Successful investors always anticipate (or manage to know) what others perceive as success (Keynes, 1936).
For researchers, WSB discussions offer a granular and dynamic perspective on the motives behind retail trading. Bradley et al. (2021, WP) find that a subset of Reddit WallStreetBets posts, “Due Diligence,” positively predict returns during their sample period. Eaton et al. (2022, JFE) discover that despite being brief, WallStreetBets forum posts strongly predict future trading by Robinhood investors, whose herding could be detrimental to market quality. Bryzgalova et al. (2023, JF forthcoming) demonstrate that WSB comments are not only responsive to retail equity trading but also reflective of their option choices.
In this blog, I will provide a systematic approach to accessing the entire archival dataset of WSB comments and conducting analytical research with this dataset. Specifically, I will demonstrate how to:
- Filter comments based on submission titles.
- Count the daily mentions of all CRSP tickers in WSB.
- Implement (high-frequency) event study on WSB comments.
Download the Dump Files as the Data Source
Just two months ago, accessing and filtering Reddit archival data is a breeze with the PushShift API. This ingenious RESTful API provides comprehensive functionality for searching Reddit data and offers powerful data aggregation capabilities.
Reddit revoked Pushshift’s access to its Data API on May 19th, 2023, citing a violation of their Data API Terms. While access to the PushShift API was partially restored for a select group of moderators in late June, most researchers were not included. The most recent emergence of PullPush, a replica of Pushshift, has provided some hope, but it is currently only a demo and its sustainability remains uncertain.
Another option for accessing Reddit data is through praw, a Python wrapper for the Reddit API. However, retrieving comments using praw can be time-consuming due to Reddit’s strict parent-children layer structure. Unpacking each layer takes time, and extracting comments from a single submission, especially on subreddits like Wallstreetbets with deep comment threads, could take up to 20 minutes or longer. Overall, praw’s iterative process of navigating through comment layers, which inherits from Reddit API, makes it barely suitable for extracting comments from WSB threads.
So I gave up the APIs or their wrappers, and decided to create my own WSB full-archive database based on the dump files shared by Watchful, an active data contributor and moderator in Reddit, at academictorrents.com.
Watchful posted torrents for Reddit comments and submissions data at academictorrents.com in February 2023. The torrent for Reddit dumps spanning from 2005-06 to 2022-12 can be accessed here, and the torrent for dumps of individual subreddits are available here. A pleasant surprise is that Watchful separately posted the torrent for dumps of Wallstreetbets at this link. That means we could directly access Wallstreetbets data without unpacking the whole Reddit universe (I was not aware of this separate torrent when handling Reddit data and wasted a lot of time on this step).
To download torrent files, you need a BitTorrent client software that can handle the downloading and uploading of files using the BitTorrent protocol. Suppose that you have successfully downloaded the zst files in the Wallstreetbets torrent link, we will proceed to handle these files in the next step.
Make The Dump Files More Accessible
The Reddit archival dataset was compressed into ZST (Zstandard) files due to their high compression ratios and fast decompression speeds. I converted the ZST file to CSV format for the sake of flexibility in my subsequent manipulations, even though Python can handle the ZST file directly. I will mainly introduce how to decompress WSB comment ZST file, and you can follow the same method to decompress the WSB submission ZST file.
Step 1: Decompress ZST Files
Since the ZST file for WSB comments is very large (4.84 GB), using code for decompressing is a more practical approach as most decompressing software cannot handle files of this size.
I modified Watchful’s codes from his GitHub repository to convert the ZST file to CSV format. The codes were already well-written, but I made revisions to ensure that the unpacking process continues even if errors occur. This is necessary for obtaining the complete archive of WSB comments.
Before converting, we need to specify three parameters.
-
Input_file_put: the path where your ZST file is.
-
Out_file_put: the path where your csv file would be.
-
fields: the fields you want to extract for each comment.
-
I specify the following variables in the
fields.- author: commenter’s Reddit ID, e.g., secondhandsondek
- parent_id: what the comment is responding to, e.g., t3_s4jw1, t1_c4b3hli, etc.
- t3_ for submission id, t_1 for comment id
- link_id: which submission the comment is responding in, e.g., t3_s4jw1
- score: number of upvotes
- created_utc: the epoch time the comment was created, e.g., 1334162803 for 2012-04-11 16:46:43 GMT
- body: the comment content: e.g., Looks like both my shorts panned out!
- id: the identifier for the comment, e.g., cv20j35
-
Over 50 variables are available for each Reddit comment. Below is a list of the majority of them. To provide readers with a better understanding of the structure of Reddit comment data and the potentially accessible variables, I shared a sample dataset at this link.
Reddit Comments Variables all_awardings author_flair_type created_utc parent_id subreddit_name_prefixed associated_award author_fullname distinguished permalink subreddit_type author author_patreon_flair edited quarantined total_awards_received author_created_utc awarders gilded removal_reason retrieved_utc author_flair_background_color body gildings score updated_utc author_flair_css_class can_gild id send_replies body_sha1 author_flair_richtext can_mod_post is_submitter steward_reports nest_level author_flair_template_id collapsed link_id stickied utc_datetime_str author_flair_text collapsed_reason locked subreddit edited_on author_flair_text_color controversiality no_follow subreddit_id author_cakeday -
To avoid code interruption, it is recommended to select only those variables that are likely to be available for every comment in WSB since 2012. This approach accounts for changes in available variables over time.
-
Codes for Decompressing ZST files
|
|
Output
The log of the unpacking progress is as follows. There are four parameters printed in the log.
- The latest timestamp of all processed comments.
- The number of processed comments.
- The number of bad lines (this might not be precise for my revision).
- The percentage of processed file size.
|
|
Assuming the codes run smoothly, you will obtain a CSV-formatted file containing all WSB comments posted between 2012-04-11 16:46:43 GMT and 2022-12-30 18:53:51 GMT.
Use the same code to decompress the WSB submission file as the comments file, but remember to re-specify the three parameters.
-
Input_file_put: the path where your submission ZST file is.
-
Out_file_put: the path where your submission csv file would be.
-
fields: the fields you want to extract for each submission. I would choose the follows.
- [’title’, ’link_flair_text’, ‘score’, ‘created_utc’, ‘id’, ‘author’, ’num_comments’, ‘permalink’]
Assuming the codes run smoothly, you will obtain a CSV-formatted file containing all WSB submissions posted between 2012-04-11 and 2023-01-01.
Step 2: Slice the WSB Comment CSV File
To improve the accessibility of WSB comments, I divided the large dump file into 94 smaller sub-files, each containing 1,000,000 lines. This slicing allows for easier and faster reading of the data compared to dealing with a single 4 GB CSV file, which can be time-consuming and CPU-intensive. The choice of 1,000,000 lines per sub-file is arbitrary and can be adjusted according to your preference.
|
|
After this step, you will obtain 94 sub-files of WSB comments in CSV format, each comprising 1,000,000 lines. It is important to note that, except for the first sub-file, the sliced sub-files do not have a header and may have a few improperly formatted lines due to delimiter issues in the beginning of the file. While this is not a significant problem, it may require skipping the initial lines, say first 50, to ensure smooth reading of the CSV file in Python.
Task 1: Filter Comments By Submission Titles
So far, we have acquired accessible WSB comments and submissions. Our first task is to extract comments from submissions that have specific submission titles. In certain cases, it is unnecessary to analyze the entire WSB universe; rather, focusing on representative and active submissions, such as “Due Diligence” mentioned in Bradley et al. (2021, WP) and “Daily Discussion” (they also include “What Are Your Moves Tomorrow” in their online appendix) utilized by Bryzgalova et al. (2023, JF forthcoming), can serve our purpose. This approach not only reduces the data size that needs to be processed but also ensures consistency and facilitates comparisons across different days.
I will show how to retrieve all the WSB comments in submissions with “Daily Discussion” in their title. In WSB, “Daily Discussion” refers to a recurring thread where users can engage in general discussions about the stock market, trading strategies, and other related topics. It is a designated space for members of the WSB community to share their thoughts, ask questions, and exchange ideas on a daily basis.
To implement this, we need first filter within the WSB submission universe, where the titles and the base36 ids of all the submissions are available. Let’s assume we designate the resulting dataframe as postdf. To facilitate the subsequent merging, we need to rename the variable for submission id from id to link_id.
With the base36 IDs of the targeted submissions, we can perform a merge operation between postdf and the WSB comments universe, which is spread across 94 separate files. We gather all the successfully merged results when merging them one by one.
As the merging process involves iterating over all the sliced comment files, we can simultaneously clean these slices. I would recommend making four modifications in this regard.
- Add a header to all sub-files to facilitate filtering comments by column names.
- Retrieve the
base36submission ID from thelink_idof each comment. Currently, they are liket3_s4jw1, we only need the part after the underscore character. - Extract the date from the UTC timestamp of each comment, enabling filtering based on specific dates.
- Add the start and end dates for each sliced file to its filename for better reference.
As the filtered results are not as big, I write them into a single CSV file WSB_DD.csv. In case it’s too big, you can definitely following the aforementioned method to slice it.
Codes for Picking Out Comments in Specified Submissions
|
|
Task 2: Count the daily mentions of all CRSP tickers
Despite the potential for higher granularity offered by WSB comments, researchers opt to use the daily counts of firms’ tickers to ensure the comparability with other retail attention measures, such as Google search trends and page clicks of firm’s wiki profile. Our second task is thus to count the WSB mentioning times for each CRSP tickers. Following Bryzgalova et al. (2023, JF forthcoming), I only count the capitalized tickers in WSB comments.
To implement this, we need first obtain all the CRSP symbols from WRDS, which is available at WRDS CRSP Stock Header Information. Note that any symbol list should work, the point is to get a symbol list you want to count the mentioning times by WSB comments.
The algorithm of implementing this are as follows.
- Load all the CRSP tickers to a dataframe
- Load all the WSB comments in “Daily Discussion” thread, which we have obtained in Task 1
- Group the dataframe for WSB comments by comment date
- For each comment date, gather all the comment text into a single string, within this string
- Use regular expressions to figure out all the capitalized words in this string
- Count the mentioned times for each capitalized word mentioned by this string
- Pick out CRSP tickers from capitalized words mentioned by this string and their mentioned times
- Save the CRSP tickers and their mentioned times to the output file
- Iterate over the comments dates
Codes for Counting Daily Mentions of all CRSP Tickers
|
|
Task 3: Implement Event Study on WSB Comments
WSB has the potential to provide granularity beyond daily frequency, allowing for analysis at an hourly, minute, or even second level, depending on researchers’ needs. The logic to implement higher frequency event study is as similar to what we did with daily frequency.
Take the hourly event study as an example. First you need a timestamp when your event happens. Then you calculate the time difference between the event timestamp and the comment timestamps, determining the hourly difference between them. At the same time, you narrow down the dataset to the desired time range, say [-12, +12] hours relative to your event. Next, you group the dataset based on the hourly gap relative to the event occurrence and apply the CRSP ticker count program, as outlined in the function countcrsp(df) in Task 2, for each hour gap.
Codes for Implementing Event Study on WSB Comments
|
|
Summary
In this blog, I present a systematic approach to accessing and analyzing comments on Reddit Wallstreetbets, which offers dynamic and granular views of retail traders when making trading decisions. Apart from studying retail attention, researchers may find it intriguing to investigate the organization and coordination among retailers, such as the roles of sophisticated leaders in the forum and the patterns of collaboration within the community.
References
- Bradley, Daniel, et al. “Place your bets? The market consequences of investment research on Reddit’s Wallstreetbets.” The Market Consequences of Investment Research on Reddit’s Wallstreetbets (March 15, 2021) (2021).
- Bryzgalova, Svetlana, Anna Pavlova, and Taisiya Sikorskaya. “Retail trading in options and the rise of the big three wholesalers.” Journal of Finance forthcoming (2022).
- Eaton, Gregory W., et al. “Retail trader sophistication and stock market quality: Evidence from brokerage outages.” Journal of Financial Economics 146.2 (2022): 502-528.
- Jakab, Spencer. Who Really Got Rich From the GameStop Revolution?. Wall Street Journal, 2022.
- Keynes, John Maynard. “The general theory of employment.” The quarterly journal of economics 51, no. 2 (1937): 209-223.