Motivation
Recently, at the request of my colleagues, I have been working on parsing the comprehensive Glassdoor dataset for 2,219 firms and gathering insights from employees residing in various states across the United States. In this blog post, I will share the detailed techniques and algorithms to fulfill this task. For readers who want to access the codes directly, please jump to this section.
Why Glassdoor
Glassdoor has been offering rich insights for practitioners, stakeholders, and researchers and seems to continue to do so in the foreseeable future.
Through anonymous reviews shared anonymously from a diverse pool of current and former employees, it offers up-to-date information influencing potential employees’ career decisions (Westfall, 2017) and guiding external investors on determining the future operating performance of firms (Huang et al., 2020 TAR). On the other hand, firms actively track reviews on them, adjusting both workplace and disclosure practices to improve their labor market image (Dube and Zhu, 2021 JAR).
The significant relevance of Glassdoor reviews is also evident in firms’ strategic actions to boost their images on this platform (Winkler and Fuller, 2019 WSJ), rendering positive reviews inevitably less informative than negative ones (Gong and Thomas, 2023 WP).
For researchers, the Glassdoor dataset serves as an invaluable source for describing firms’ workplace environments and labor market conditions at the more challenging-to-observe micro-level, as opposed to the aggregated firm-level. More importantly, it offers insights into the work experiences of employees in lower hierarchies of the firm, a demographic that is less covered by the majority of established datasets in existing labor Accounting/Finance/Economic studies due to data limitation. For example, Pacelli et al. (2023, WP) use Glassdoor culture ratings to support the notion that including culture information in job postings aids firms in attracting job seekers and maintaining a lower turnover rate. Similarly, Sockin et al. (2021 WP) show that employees are more likely to share negative workplace information on Glassdoor after the passage of state laws prohibiting non-disclosure agreements (NDAs) for concealing unlawful workplace conduct.
Data Input and Description of Glassdoor Parsing Task
Data Input
The data input is as follows. It consists of 2,219 distinct company-state pairs that require the Glassdoor review data.
| Index | conml | state | gvkey | companyid |
|---|---|---|---|---|
| 1 | AAR Corp | IL | 1004 | 394 |
| 2 | American Airlines Group Inc | TX | 1045 | 2021732 |
| 3 | AVX Corp. | SC | 1072 | 3262 |
| 4 | Abbott Laboratories | IL | 1078 | 428 |
| 5 | Aceto Corp | NY | 1094 | 631 |
| 6 | Acme United Corp | CT | 1104 | 656 |
| 7 | BK Technologies Corp | FL | 1117 | 26018 |
| 8 | Adams Resources & Energy Inc. | TX | 1121 | 751 |
| 9 | Advanced Micro Devices Inc | CA | 1161 | 881 |
| … | … | … | … | … |
| 2213 | EnSync Inc | WI | 272699 | 932520 |
| 2214 | FutureFuel Corp | MO | 287462 | 1694747 |
| 2215 | Vislink Technologies Inc | FL | 289735 | 1065975 |
| 2216 | Aevi Genomic Medicine Inc | PA | 293754 | 66112 |
| 2217 | LyondellBasell Industries NV | TX | 294524 | 1667126 |
| 2218 | Element Solutions Inc | FL | 315318 | 2005381 |
| 2219 | Dorian LPG Ltd | CT | 317264 | 2066589 |
Description of Task
To meet my colleagues’ research requirements, I need to request data for each company-state pair listed in the table above. Taking “AAR Corp-IL” as an example, the desired data request procedures are as follows.
- Filter out all Glassdoor reviews for the firm “AAA Corp” by reviewers residing in Illinois.
- For each review sustaining the selection criteria,
- Parse the reviewer’s ratings on the firm, the review content in text, the timestamps, Glassdoor-assigned subject label for the review, and other relevant information available in the website
- Determine the reviewer’s current job position, his/her employment status in this company, and the city of the commented office.
Workflows for Glassdoor Parsing
After analyzing the structure of the Glassdoor website and its anti-crawler designs, I have identified 10 procedures to request the required dataset. I will continue to use ‘AAR Corp-IL’ as an example to illustrate these procedures.
Step 1: Find the company’s ID assigned by Glassdoor and get the review page of this company
-
Search the name of the company “AAR Corp” in Glassdoor and record the best match
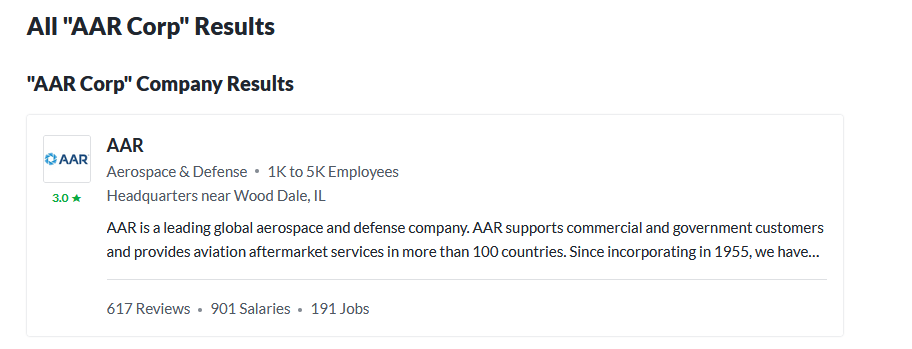
Figure 1: Search Company in Glassdoor
Step 2: Open the review page of this company, then record its screen name and ID in Glassdoor
-
The review page of “AAR Corp” is displayed in the following figure. From the url of the review page,
https://www.glassdoor.com/Reviews/AAR-Reviews-E4.htm, its screen name and ID are- CompanyScreenname: AAR
- CompanyID: 4
-
The formatted url after adding subject filtering would be
https://www.glassdoor.com/Reviews/{CompanyScreenname}-Reviews-E{CompanyID}.htm
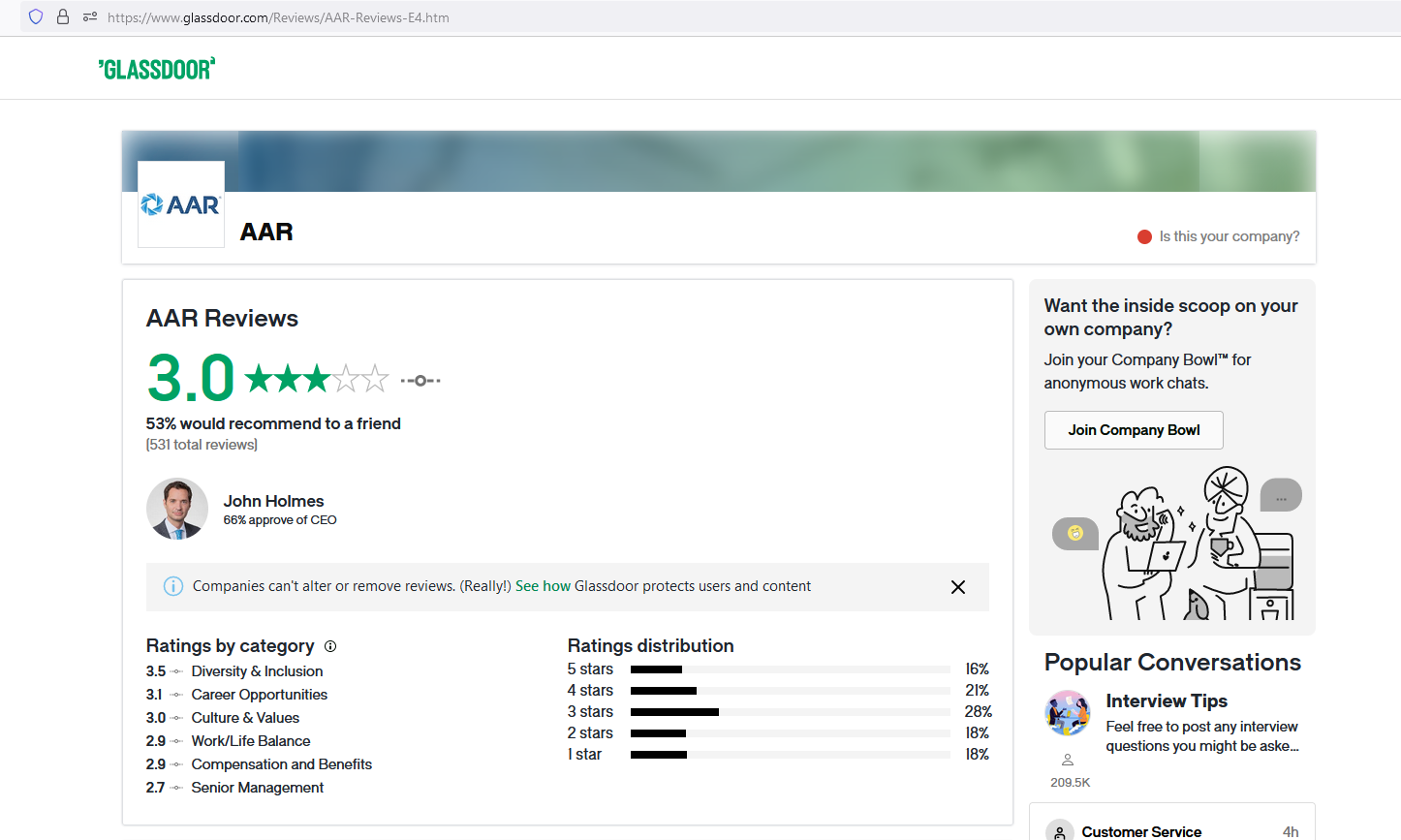
Figure 2: Review Page
Step 3: Filter the reviews by subject of the review content
-
As the Glassdoor-assigned subject label for each review is not included in the review metadata but can only be accessed through subject filtering, I need to parse the reviews subject by subject to obtain the Glassdoor-assigned subject labels.
-
Take the parsing of reviews for ‘AAR Corp’ with a Glassdoor-assigned subject of Work Life Balance as an example. The filtered review page is displayed as the following figure.
-
From the url of the filtered review page,
https://www.glassdoor.com/Reviews/AAR-Reviews-E4.htm?filter.searchCategory=WORK_LIFE_BALANCE, the subject filter is achieved through adding an additional parameterfilter.searchCategorywith a value of the Glassdoor-assigned subject ID for the subjectWORK_LIFE_BALANCEto the base urlhttps://www.glassdoor.com/Reviews/AAR-Reviews-E4.htm. That said, the new parameter here is- SubjectID: WORK_LIFE_BALANCE
-
The formatted url after adding subject filtering would be
https://www.glassdoor.com/Reviews/{CompanyScreenname}-Reviews-E{CompanyID}.htm?filter.searchCategory={SubjectID}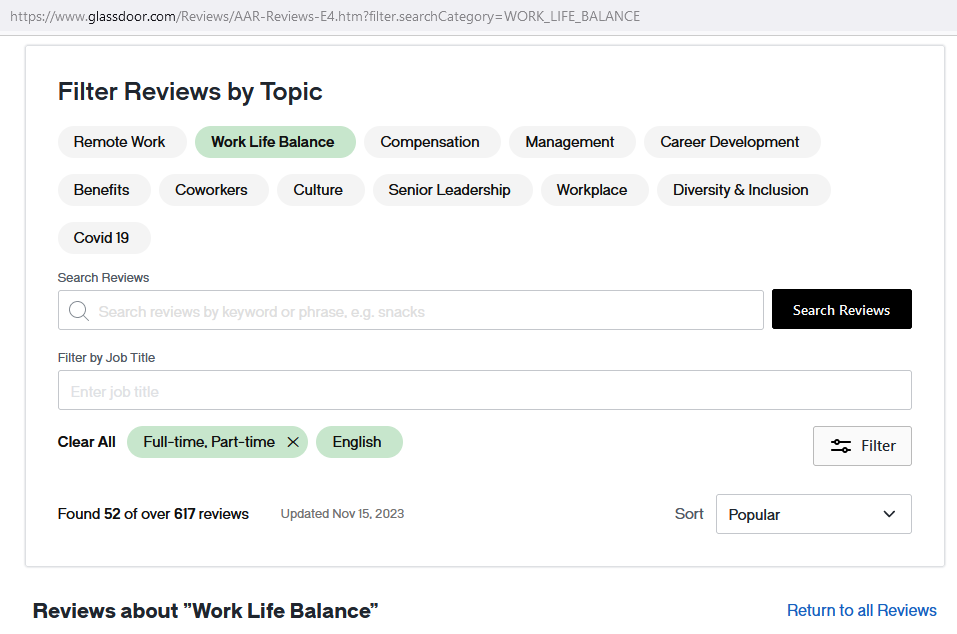
Figure 3: Filter Review by Topic
Step 4: Filter the reviews by the geolocation of the employees
- Remember that we want Glassdoor reviews for the firm “AAA Corp” by reviewers residing in Illinois. The filtered review page is displayed as the following figure.
- From the url of the filtered review page,
https://www.glassdoor.com/Reviews/AAR-Illinois-Reviews-EI_IE4.0,3_IL.4,12_IS302.htm, the geolocation filter is achieved through accessing a new geolocation-based review page. - The parameters of this geolocation-based review page include:
- CompanyScreenname: AAR
- CompanyID: 4
- GeolocationScreenName: Illinois
- GeolocationID: 302
- Note that requesting
https://www.glassdoor.com/Reviews/AAR-Illinois-Reviews-EI_IE4.0,3_IL.4,12_IS302.htmis equivalent to requestinghttps://www.glassdoor.com/Reviews/AAR-Illinois-Reviews-EI_IE4._IS302.htmin Glassdoor. - Therefore, the formatted url after adding geolocation filtering would be
-
https://www.glassdoor.com/Reviews/{CompanyScreenname}-{GeolocationScreenName}-Reviews-EI_IE{CompanyID}._IS{GeolocationID}.htm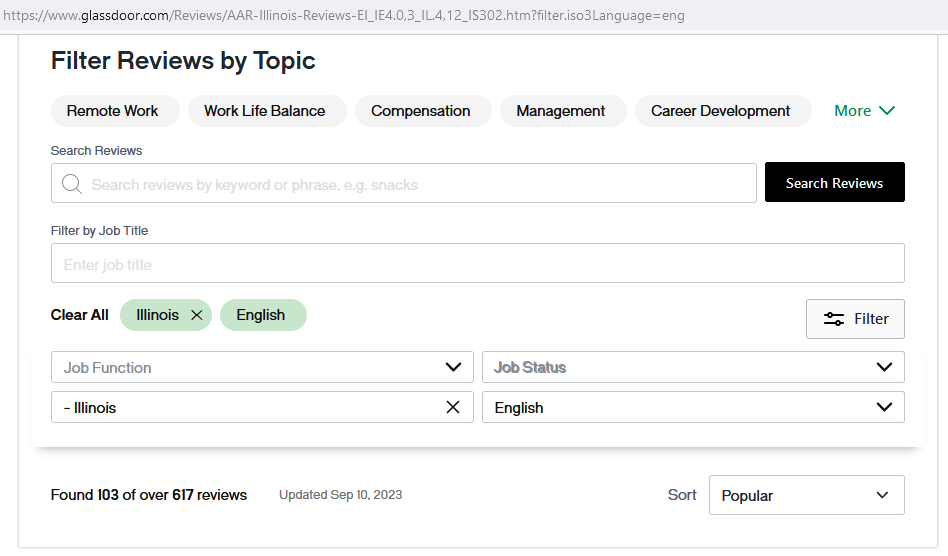
Figure 4: Filter Review by Geolocation
-
Step 5: Combine the geolocation filter and subject filter
- While Glassdoor redirect urls when adding the subject filter manually on the page conditional on the geolocation filter, one can apply both filters simultaneously by using a URL like
https://www.glassdoor.com/Reviews/AAR-Illinois-Reviews-EI_IE4.0,3_IL.4,12_IS302.htm?filter.searchCategory=WORK_LIFE_BALANCE - The formatted url when applying both filters would be
https://www.glassdoor.com/Reviews/{CompanyScreenname}-{GeolocationScreenName}-Reviews-EI_IE{CompanyID}._IS{GeolocationID}.htm?filter.searchCategory=WORK_LIFE_BALANCE
Step 6: Figure out how to jump to the next page with the combined filters
- After several little experiment, I found to jump to the 2nd page of the double-filtering results could be achieved with url like
https://www.glassdoor.com/Reviews/AAR-Illinois-Reviews-EI_IE4.0,3_IL.4,12_IS302_IP2.htm?filter.iso3Language=eng. The new parameter is the Page index, which takes a value of 2 in this case. - Correspondingly, the formatted url would be
https://www.glassdoor.com/Reviews/{CompanyScreenname}-{GeolocationScreenName}-Reviews-EI_IE{CompanyID}._IS{GeolocationID}_IP{Page}.htm?filter.searchCategory=WORK_LIFE_BALANCE
Step 7: Parse all the valid reviews that sustain the selection criteria
-
Till now, we finally could parse the content of each Glassdoor review. The meta data of each review is stored in one
jsonnamedapolloStateembedded in the webpage. -
I list an example review meta data as follows. The readers may find all properties provided for each review.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66"apolloState":{ "EmployerProfile:7925": { "id": 7925, "__typename": "EmployerProfile" }, ... "ROOT_QUERY":{ "__typename":"Query", "employer({\"id\":7853})":{ "__ref":"Employer:7853" }, ... "reviews":[ { "__typename":"EmployerReviewRG", "isLegal":true, "reviewId":81554455, "reviewDateTime":"2023-11-05T08:43:00.947", "ratingOverall":5, "ratingCeo":"APPROVE", "ratingBusinessOutlook":"POSITIVE", "ratingWorkLifeBalance":5, "ratingCultureAndValues":5, "ratingDiversityAndInclusion":5, "ratingSeniorLeadership":5, "ratingRecommendToFriend":"POSITIVE", "ratingCareerOpportunities":5, "ratingCompensationAndBenefits":5, "employer":{ "__ref":"Employer:7853" }, "isCurrentJob":true, "lengthOfEmployment":1, "employmentStatus":"REGULAR", "jobEndingYear":null, "jobTitle":{ "__ref":"JobTitle:17617" }, "location":{ "__ref":"City:1147436" }, "originalLanguageId":null, "pros":"I work in eBay's Advertising business. Biggest pro for me joining this company has been the amazing culture across the company and in this business organization. People are very committed to collaboration and partnership, helping each other succeed in our mission to delivering great experiences to our buyers and sellers. Management has been great. Compensation is very competitive. The work environment if you live close to an office is hybrid. There is a very good vibe coming into the office, seeing coworkers and making unexpected connections. I personally see a really good effort toward hiring a diverse workforce and am super proud of being part of such a company.", "prosOriginal":null, "cons":"The hiring process took a bit longer than I had hoped. At the same time, I understand that the business wanted to take the care to make sure that they are hiring the right people. I appreciate and respect that. For me, the rationale for this was shared with me and I really appreciated the transparency.", "consOriginal":null, "summary":"Outstanding Experience Joining eBay in 2023", "summaryOriginal":null, "advice":null, "adviceOriginal":null, "isLanguageMismatch":false, "countHelpful":0, "countNotHelpful":0, "employerResponses":[ ], "featured":true, "isCovid19":false, "topLevelDomainId":1, "languageId":"eng", "translationMethod":null }, ... ] } }
Step 8: Figure out the job position and office location of each reviewer
-
In the review metadata, job positions and office locations are stored as Glassdoor identifiers. We must identify the dictionary that maps these identifiers to their corresponding text-formatted content.
-
The good thing is that position and city dictionaries are also embedded in the
jsonnamedapolloState.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30"apolloState":{ "EmployerProfile:7925": { "id": 7925, "__typename": "EmployerProfile" }, ... "City:1147436":{ "id":1147436, "__typename":"City", "type":"CITY", "name":"San Jose, CA" }, "JobTitle:50838":{ "id":50838, "__typename":"JobTitle", "text":"Sales Associate" }, "City:3756853":{ "id":3756853, "__typename":"City", "type":"CITY", "name":"USAR Center, NC" }, "JobTitle:6349734":{ "id":6349734, "__typename":"JobTitle", "text":"Authentication Center Generalist" }, ... }
Step 9: Write all the extracted reviews to a CSV file, and iterate Step 1 to Step 8, page by page and subject by subject.
- Till now, we have finished the Glassdoor review parsing for the first line ‘AAR Corp-IL’.
Step 10: Repeat Steps 1 through 9 for the remaining lines in the input data.
Three Remaining Questions
Search Firm’s Glassdoor-Assigned ID and Screen Name
Remember that in Step 1, we only have the company name in the input data, but to access the company’s review page https://www.glassdoor.com/Reviews/{CompanyScreenname}-Reviews-E{CompanyID}.htm, we need the CompanyScreenname and CompanyID parameters.
The analysis of the website structure suggests that Glassdoor provides built-in APIs for searching these parameters with text input. The formatted url for the most effective API is as follows, with the parameter querystring as the the company names from the data input.
https://www.glassdoor.com/searchsuggest/typeahead?numSuggestions=8&source=GD_V2&version=NEW&rf=full&fallback=token&input={querystring}
For example, you can assign the querystring with a value of AAR Corp, and request url https://www.glassdoor.com/api-web/employer/find.htm?autocomplete=true&maxEmployersForAutocomplete=10&term=AAR%20Corp. What you would get is as follows.
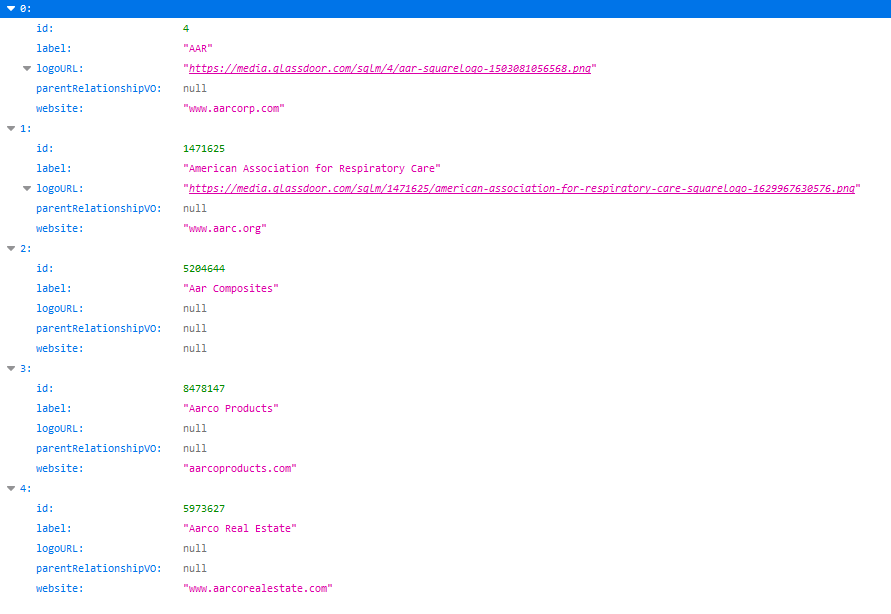
The returned result indicates that the most likely screen name for AAA Corp on Glassdoor is AAR, and its Glassdoor-assigned ID is 4, both align with our manual search on the website.
You could also use another built-in Glassdoor API as the backup. The usage is as similar.
https://www.glassdoor.com/api-web/employer/find.htm?autocomplete=true&maxEmployersForAutocomplete=10&term={querystring}.
Dictionaries For Glassdoor Geolocation and Subject Filtering
Remember that in Step 4, we need the parameters GeolocationScreenName and GeolocationID for filtering based on the geolocation.
https://www.glassdoor.com/Reviews/{CompanyScreenname}-{GeolocationScreenName}-Reviews-EI_IE{CompanyID}._IS{GeolocationID}.htm?filter.searchCategory=WORK_LIFE_BALANCE
Similarly, in Step 3, we need the parameter SubjectID for filtering based on content subject.
https://www.glassdoor.com/Reviews/{CompanyScreenname}-Reviews-E{CompanyID}.htm?filter.searchCategory={SubjectID}
After analyzing, I found both dictionaries are stored as json embedded in the Glassdoor webpage.
To make everyone’s life easier, I just share these two dictionaries freely with the following links.
-
Glassdoor Geolocation Dictionary: this link
-
Given the comprehensive coverage of Glassdoor’s dropdown menu for geolocations (6404 distinct areas worldwide), its location filter is effective not only for U.S. locations but also for quite some cities and countries worldwide.
-
Given that my colleagues’ research needs only need the US state level geolocation filters, I got a sub-dictionary exclusively for states in the US.
- Readers can access this US state-level geolocation dictionary at this link.
-
The dictionary for US states looks like the following. For example, for state
ALin my data input, its screen name in Glassdoor isAlabamaand the corresponding Glassdoor-assigned location ID is105.Glassdoorid screenname state_ab 105 Alabama AL 496 Alaska AK 483 Arizona AZ 1892 Arkansas AR 2280 California CA 2519 Colorado CO … … … 481 Wisconsin WI 1258 Wyoming WY
-
-
Glassdoor Subject Dictionary: this link
- There are in total twelve subjects in Glassdoor, and the dictionary for mapping their screen names to Glassdoor-assigned IDs is as follows.
__typename displayName enumValue ReviewCategory Remote Work REMOTE_WORK ReviewCategory Work Life Balance WORK_LIFE_BALANCE ReviewCategory Coworkers COWORKERS ReviewCategory Culture CULTURE ReviewCategory Benefits BENEFITS ReviewCategory Career Development CAREER_DEVELOPMENT ReviewCategory Compensation COMPENSATION ReviewCategory Management MANAGEMENT ReviewCategory Workplace WORKPLACE ReviewCategory Senior Leadership SENIOR_LEADERSHIP ReviewCategory Diversity & Inclusion DIVERSITY_AND_INCLUSION ReviewCategory Covid 19 COVID
- There are in total twelve subjects in Glassdoor, and the dictionary for mapping their screen names to Glassdoor-assigned IDs is as follows.
Remove Overlays and Rotate Proxies To Keep Parser Alive
With an idea of ‘Give before you get’, Glassdoor displays an overlay before granting access to its review archives. Without additional intervention, you need to log in and provide information about your job and salary before gaining access to the reviews.
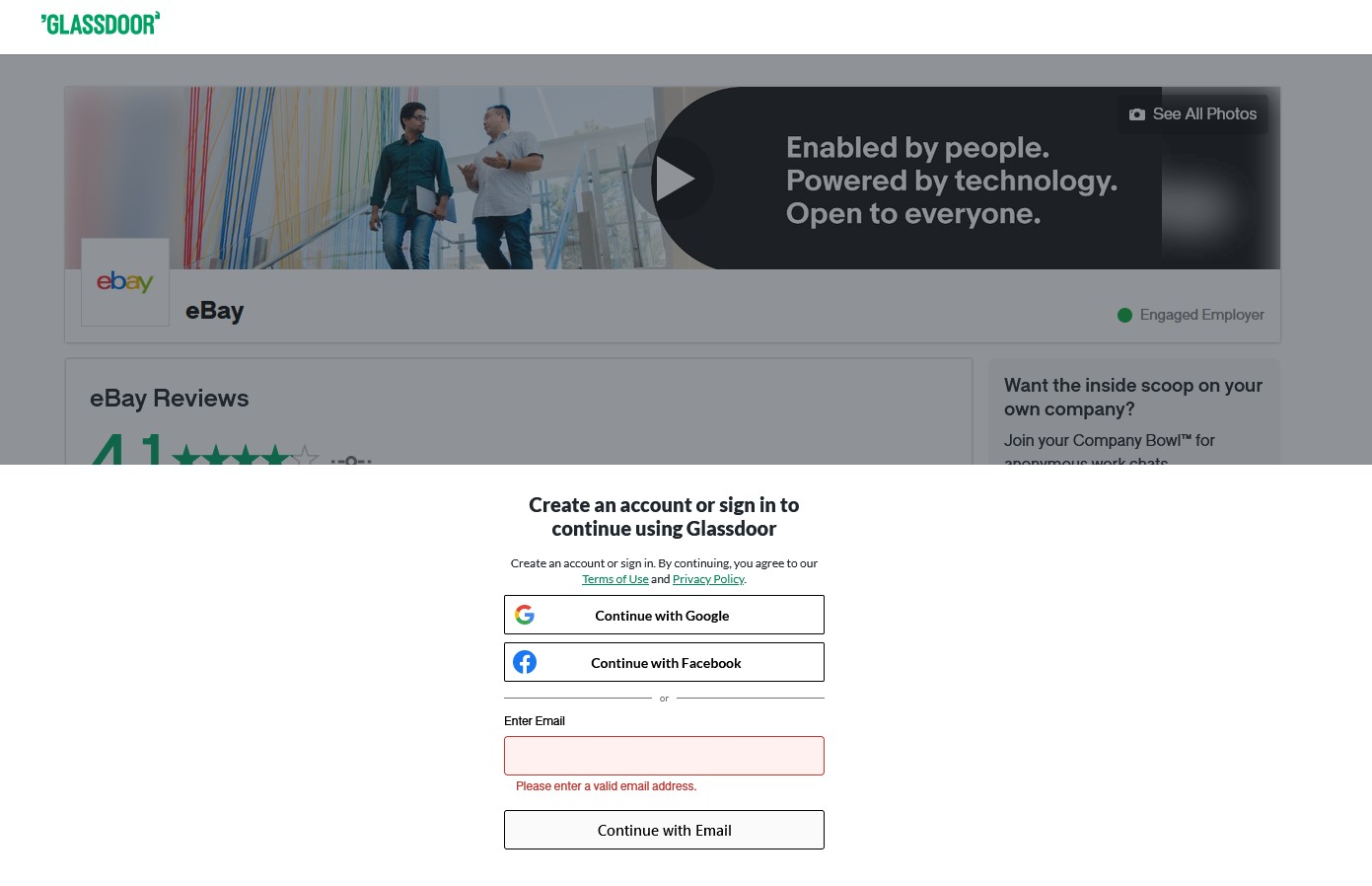
Fortunately, the blog post from ScrapFly provides the following JavaScript code, which sets a few global CSS styles to hide the overlay, physically removes the overlays, and enables the web scraper to conveniently view and inspect the web page.
|
|
In addition, considering Glassdoor’s the anti-crawler designs, we need to rotate the request agents to keep the parser alive.
For parsers with low volume demands, I recommend building your Glassdoor parsers on the infrastructure provided by ScrapFly, which offers 5,000 times of free request quota. With this infrastructure, you can outsource overlay removal and agent rotation to its API, which allows you to focus more on your personalized parsing needs.
Five Modules of My Glassdoor Parser
Having documented all the necessary analyses of the Glassdoor website, we could finally deploy the parser. Suppose we are working with the parser for company AAR Corp with reviewers residing in Illinois.
To deploy the Glassdoor Parser, I wrote 5 main modules as follows.
Module 1: Import the Infrastructure From Scrapfly
|
|
- The page source of the Glassdoor page available for subsequent analysis is returned with this function.
Module 2: Search Firm’s Glassdoor-Assigned ID and Screen Name
- I by default only use the top search result in the returned json. Readers can modify with their needs.
|
|
- this step returns parameter
employerandemployer_id.
Module 3: Extract Meta Data of Reviews and Dictionaries for Reviewers’ Job Positions and Working Cities
- The input of this step is the page source of the Glassdoor webpage.
|
|
- The dictionaries for reviewers’ job positions and working cities are recorded in two separate csv files,
f"{employer}_{employer_id}_jobtitle.csv"andf"{employer}_{employer_id}_city.csv"in this step. - The meta data for reviews is returned as
reviewsfor further formatting.
Module 4: Format and Record Meta Data for Reviews
- To keep data returned from different pages consistent, I fixed the columns from review meta data.
|
|
- I also add the identifiers from data input for potential further matching with other datasets.
- The review data is saved in a csv file
f"{employer}_{employer_id}.csv"in this step.
Module 5: Add Filters for Glassdoor Geolocation and Subject
As the keys in the subject dictionary are iterable and self-explanatory, I load the Glassdoor-assigned IDs for the 12 subjects into a list.
The dictionary For states in the US is loaded from a csv file glassdoorstateids.csv, which is available at this link.
|
|
Deploy the Parser
Data Input
-
Original Data Input:
gvkey_companyid_state_list_final_nwlk_withConm.csv. Example lines are as follows.gvkey state companyid conml 1004 IL 394 AAR Corp 1045 TX 2021732 American Airlines Group Inc 1072 SC 3262 AVX Corp. -
Augmented Data Input:
glassdoorstateids.csv, available at this link. Example lines are as follows.Glassdoorid screenname state_ab 105 Alabama AL 496 Alaska AK 483 Arizona AZ
Codes
|
|
Data Output
-
Review Data with Company Identifiers, e.g.,
AVX Corp._4345.csv. Example lines are as follows.employer gvkey companyid glassdoorname stateid state_ab statename cate reviewcount isLegal reviewId reviewDateTime ratingOverall ratingCeo ratingBusinessOutlook ratingWorkLifeBalance ratingCultureAndValues ratingDiversityAndInclusion ratingSeniorLeadership ratingRecommendToFriend ratingCareerOpportunities ratingCompensationAndBenefits isCurrentJob lengthOfEmployment employmentStatus jobEndingYear pros prosOriginal cons consOriginal summary summaryOriginal advice adviceOriginal isLanguageMismatch countHelpful countNotHelpful employerResponses isCovid19 topLevelDomainId languageId employer.__ref jobTitle.__ref location.__ref AVX Corp. 1072 3262 AVX 3411 SC SouthCarolina REMOTE_WORK 35 TRUE 55512860 2021-11-17T18:38:49.553 4 APPROVE POSITIVE 4 3 2 2 POSITIVE 4 2 TRUE 4 REGULAR Most management cares about their people Too many political barriers and lack of accountability Growing and room for growth Give more incentives across the board and hold management/others accountable. FALSE 0 0 [] FALSE 1 eng Employer:4345 JobTitle:31261 City:1155193 AVX Corp. 1072 3262 AVX 3411 SC SouthCarolina REMOTE_WORK 35 TRUE 52598500 2021-09-15T11:30:21.503 1 APPROVE NEGATIVE 2 1 1 1 NEGATIVE 1 1 TRUE 0 REGULAR nothing to tell, its just a job selfish managers, no raises, terrible place to work, no accountability smh FALSE 1 0 [] FALSE 1 eng Employer:4345 JobTitle:328345 City:1155193 -
Dictionary for Reviewers’ Job Positions, e.g.,
AVX Corp._4345_jobtitle.csv. Example lines are as follows.JobID __typename JobTitle 5619775 JobTitle QA Final Inspection 36980 JobTitle Production 31261 JobTitle Engineer -
Dictionary for Reviewers’ Office Locations, e.g.,
AVX Corp._4345_jobtitle.csv. Example lines are as follows.CityID __typename type City 1155247 City CITY Myrtle Beach, SC 1155193 City CITY Greenville, SC 1155247 City CITY Myrtle Beach, SC
Summary
In this blog post, I analyzed the structure of the Glassdoor website and presented the major techniques and considerations for writing the Glassdoor parser. Most importantly, the blog post provides a streamlined workflow and complete code for deploying the Glassdoor parser on a sample that includes over 2,000 distinct firms.
Main References
- Dube, Svenja, and Chenqi Zhu. “The disciplinary effect of social media: Evidence from firms’ responses to Glassdoor reviews.” Journal of Accounting Research 59, no. 5 (2021): 1783-1825.
- Gong, Ping, and Jacob K. Thomas. “Thumb on the Scale: Do Employers Manage Glassdoor Reviews?.” Available at SSRN 4460625 (2023).
- Huang, Kelly, Meng Li, and Stanimir Markov. “What do employees know? Evidence from a social media platform.” The Accounting Review 95, no. 2 (2020): 199-226.
- Pacelli, Joseph, Tianshuo Shi, and Yuan Zou. “Communicating Corporate Culture in Labor Markets: Evidence from Job Postings.” Available at SSRN 4235342 (2022).
- Sockin, Jason, Aaron Sojourner, and Evan Starr. “Non-disclosure agreements and externalities from silence.” (2023).
- Westfall, B. “How Job Seekers Use Glassdoor Reviews.” Software Advice, 2017. Available at https://www.softwareadvice.com/resources/job-seekers-use-glassdoor-reviews/.
- Winkler, R., and A. Fuller. “How Companies Secretly Boost their Glassdoor Ratings.” The Wall Street Journal, 2019. Available at https://www.wsj.com/articles/companies-manipulateglassdoor- by-inflating-rankings-and-pressuring-employees-11548171977.