Introduction
I find Google Search is a fairly nice platform as an integrated information source, especially when the information that you want has not been collected by the existed database, or - you think it’s not worthwhile to pay for it.
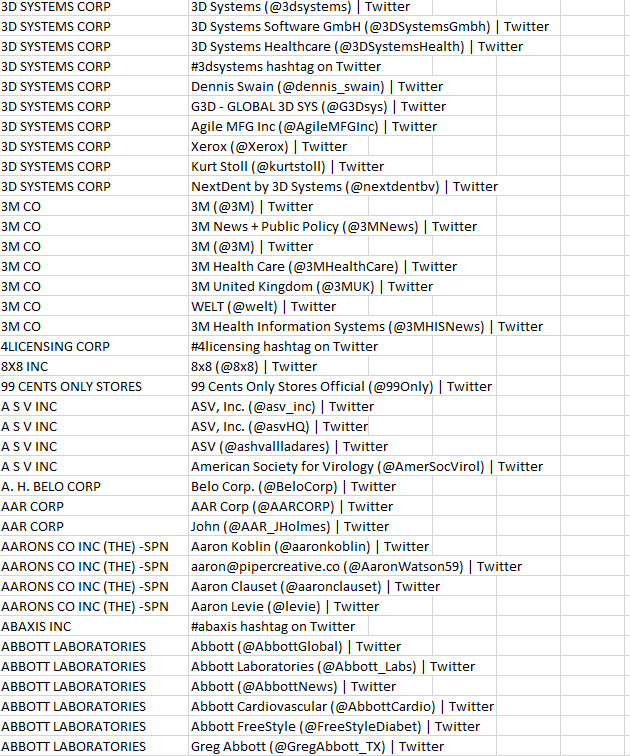
For example, in my last project, I need to collect firms’ Twitter account for 3000+ different companies. However, there is no established database which I have access to.
The solution I found is to submit firm name or firm Ticker plus ‘Twitter Account’ to Google search, record the most relevant search results, and write them into my excel sheet - That is basically what I would do if I am hand-collecting the data and means huge workload if I actually do it. But if I can write a script to automate this procedure and let the computer repeat this procedure for 3000+ times, things would be much easier.
The most exciting part of this little idea is that it has great ability to be transplanted into another project. This year when I wanted to collect some firms’ domain (most of them are not listed and thus not available in popular databases) and connect it to the IP range database, I just took out the script that was written for the aforementioned Twitter account searching from my code warehouse, changed two parameters, and immediately get the data.
In this blog, I will introduce how to write this script to utilize Google Search as an integrated information source.
Step 1: Initialize an browser
Firstly, we need to open a headless browser, jump to the google search page, and click whatever the Google requests to proceed with the searching. In my case, I need to agree with the cookies settings.
Next, we search a random thing (here I use “test”) to enter the normal search page, rather than the start page. If necessary, you may want to have your results displayed in English.
Till now we have finished the initialization of the browser. This step returns an initialized driver for later use.
Code
|
|
Step 2: Submit Search Words
As the search box has been occupied by the word we inserted before, we need to delete it first and then insert new search word. The search word will be composed of two parts:
- The
itemwe need to iterate over the list - The
keywordwe need to make sure the search results are relevant for our purpose
For example, when I want to search the domain of a series of firms, item is the firm’s name (e.g., BlackRock Inc.) and keyword is “website” or " domain" or whatever you think would be relevant.
This step returns the element tree of the webpage which includes the search results, html, ready for the further analyzing.
|
|
Step 3: Analyze and Save Search Results
With the webpage containing search results in hand, we just need pick out the elements we need from the element tree html. Typically, you could first get the link and title for each result and then select out what you think would be the most relevant.
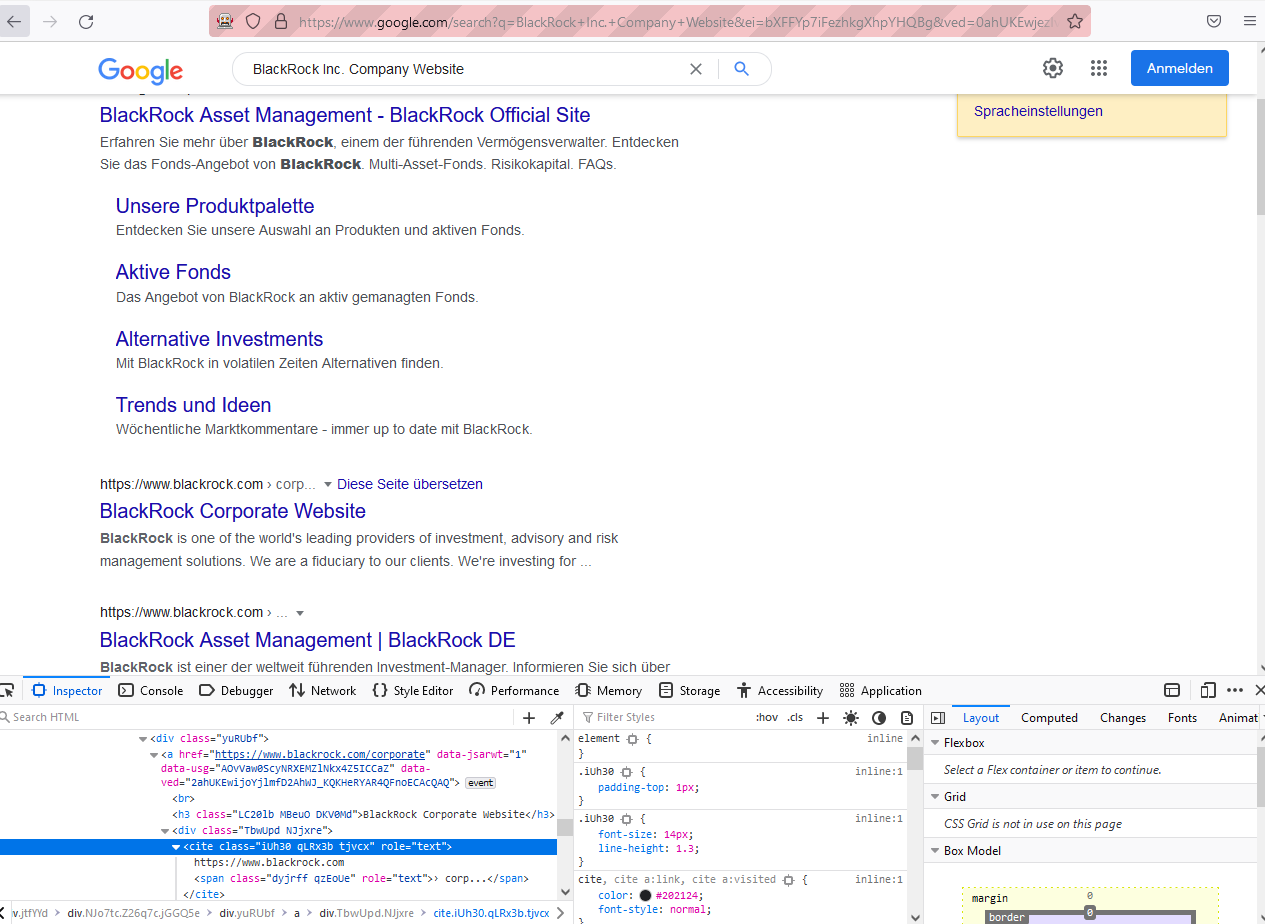
For example, I assume that the first non-advertisement search result is the most relevant one, so I just pick it out and write it into my sheet, whose name is defined by the parameter savefile.
The identifier here is to make sure you can easily attach the search results with the existed information. Here I use [itemid,item], which could uniquely identify each observation in my before-search sheet.
Code
|
|
Sometimes, you may get multiple results you desire in the same page. In such case, just iterate over each of them and write into the spreadsheet one by one. Of course, filtering the search results using your personalized rule is perfectly possible.
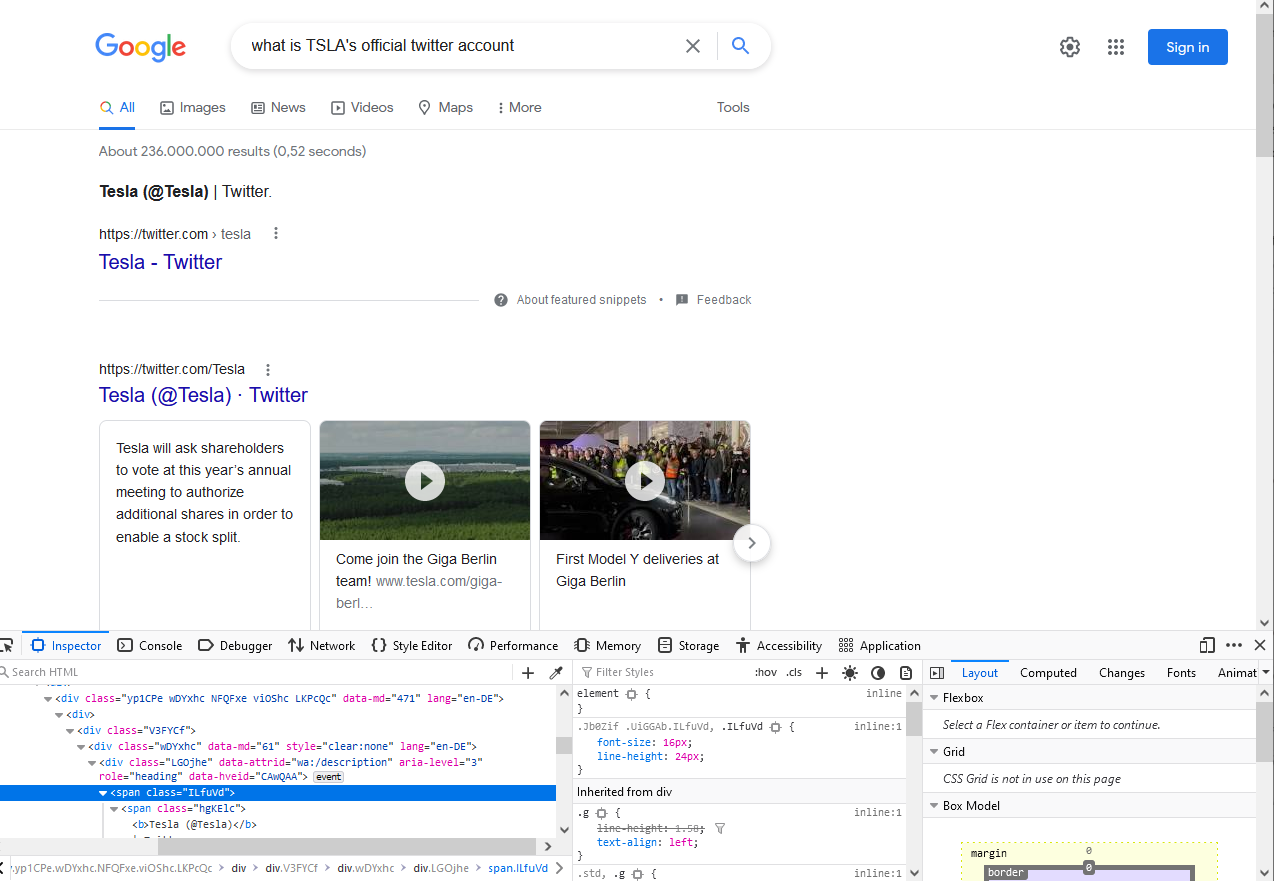
Apparently, you need further check with the above fuzzy search. But on the other hand, you may ask Google in a more precise way 😈.
For example, when checking TESLA’s official Twitter account, you can just put what is TSLA's official twitter account in the search box. Whenever she has a clear-cut answer, the nice Google will return it to you on the top of the searched results.
Step 4: Iterate over the Search List
Typically my search lists have item id and item name in the first and second column respectively. I iterate each line of my search list, put item id and item name as my identifier, and execute Step 1 - Step 3 for each line. If there is any exceptions, I pass the line and put the error line into a separated file for later check.
The definitions of main parameters are as following.
basefile: the search list, typically contains the search it and its idsavefile: the spreadsheet that stores the search results, typically in `csv’ formaterrorfile: the file that you store items which aren’t successfully searchedkeyword: the word you add after the search item to make the search results relevant
Code
|
|
Sample Results
Codes
|
|