Motivation
From my experience of reading papers and listening to seminars, I found anecodotes are crucial for people to establish their “first impression” about the credibility of the story. With proper anecdotes, the speaker is less likely to be asked many clarification questions or be questioned the necessity of conducting their following analysis. In addition, anecodes can help the author to know better about the institutional background and propose more reasonable research design.
As far as I know, Wall Street Journal inspired quite some top jornal articles. For example, Zhu (2019 RFS) is very related with a 2014 WSJ article which documents how the satellite images capturing retailors’ parking lots can give precise inter-period performance estimation about the firms. A 2013 WSJ article which shows how hedge fund managers gain edges from big data is highly relevant to Katona et al. (2018 WP, MS R&R) and Mukherjee et al. (2021 JFE).
In this blog, I will show how to parse the search results form WSJ website and how to formalize them for further textual analysis.
Analysing WSJ Website
To enable the script obtaining the information automatically, we need to get to know how we access the information manually.
Step 1: Login in WSJ Account
Obviously, the first thing is to open an active session with enough authority to access the arctiles.

Figure 1: Login In
Step 2: Accept the Website’s Cookies Policy
In many websites, only saving the cookies after logining in to keep the logining status is enough for freely accessing the data. For WSJ website, you need in addition to agree its Cookies policy to keep the session active.

Figure 2: Accept Cookies
The parameters will be posted to the origin url https://www.wsj.com/search in the format of a dictionary:
“{"query":{"not":[{"terms":{"key":"SectionType","value":["NewsPlus"]}}],"and":[{"full_text":{"value":"twitter","parameters":[{"property":"headline","boost":3},{"property":"Keywords","boost":2},{"property":"Body","boost":1}]}},{"terms":{"key":"Product","value":["WSJ.com","WSJ Blogs","WSJ Video","Interactive Media","WSJ.com Site Search","WSJPRO"]}},{"date":{"key":"UpdatedDate","value":"2020-06-30T00:00:00+00:00","operand":"GreaterEquals"}}]},"sort":[{"key":"liveDate","order":"desc"}],"count":20}/page=0”
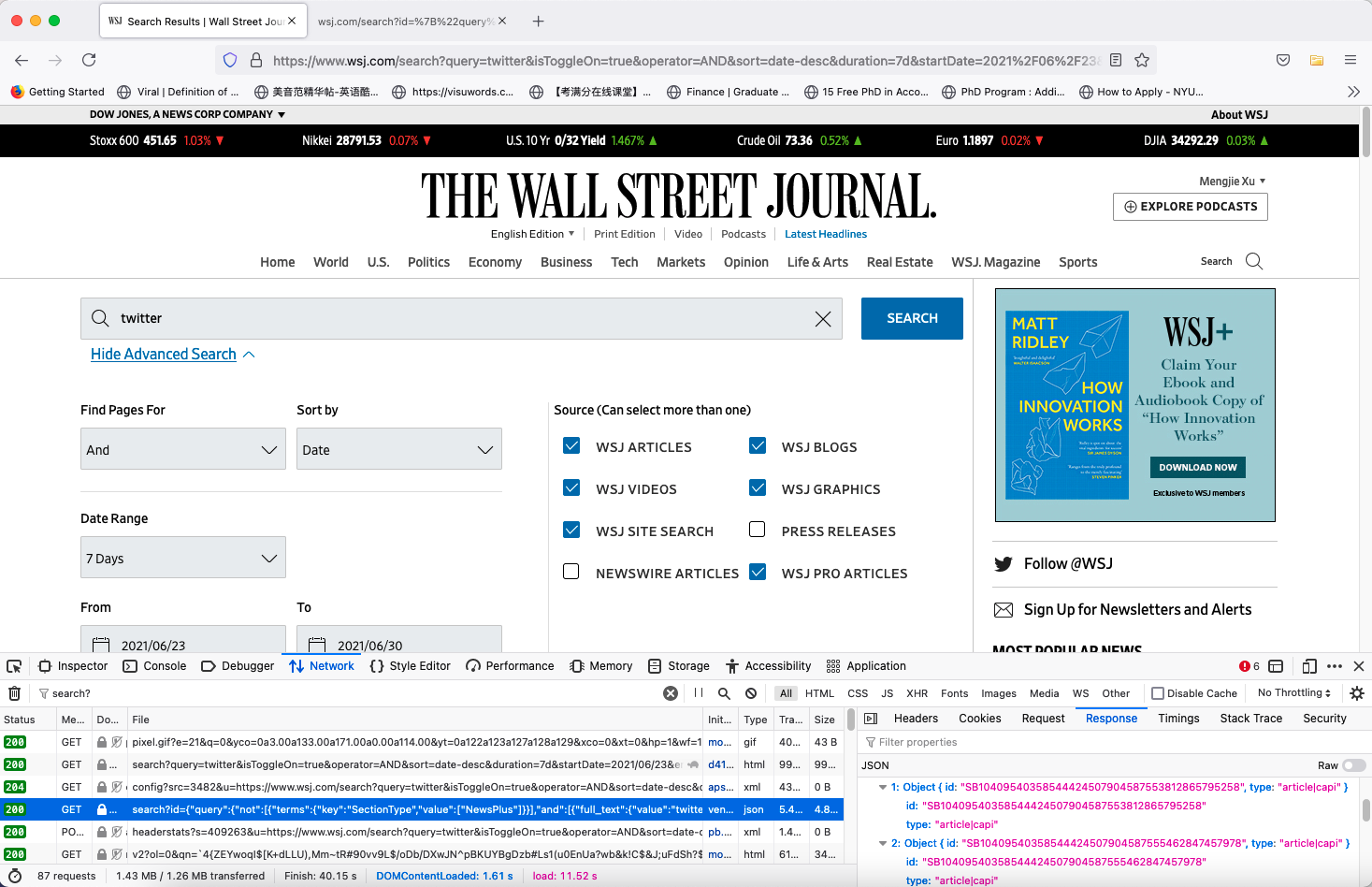
Figure 3: Input Search Parameters
The returned search result is in json format. We name the root of the json as root. There are three main parts in the returned json:
- Posted Paremeters
- Keywords
- Start Date (The latest day is the default end date)
- Current Page
- Page Information
page = root['data']['linksForPagination']
- Number of articles that fit the search parameters
page['total']
- Current Page
page['self']
- First Page
page['first']
- Last Page
page['last']
- Next Page
page['next']
- Article List in the Curent Page
collection = root['collection']
- Each article is represented by two parameters
- Article ID
e.g., collection[0]['id'] for the first article
- Article Type - Typically is article|capi
e.g., collection[0]['id'] for the first article

Figure 4: Returned Json - Article List
Step 4: Get Article Information Based on Article ID
The two key parameters will be posted to the origin url https://www.wsj.com/search:

Figure 5: Returned Json - Article Info
There is a plenty of information about the article in the returned json (Named info). The features I take are:
- Section Name
info['articleSection']
- Authors
info['byline']
- Headline
info['headline']
- Headline in Print Version
info['printedition_wsj_headline']
- Summary
info['summary']
- Article Url
info['url']
- Word Count
info['wordCount']
- Created Time
info['timestampCreatedAt']
- Print Time
info['timestampPrint']
Step 5: Download Articles
All we need to do in this step are :
- Open the link for each article
- Extract all relevant text content
- Write the text content into the specified file
Crawl WSJ
For now, we have made clear three main issues for the script to execute automatically:
- Where to post - The origin url
- What to post - Key Parameters
- What to get - Returned Json
The only thing left is to write the script out and execute it.
Code I: Get Cookies
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
from selenium import webdriver
import time
import json
driver = webdriver.Firefox(executable_path='/Users/mengjiexu/Dropbox/geckodriver')
# Insert WSJ Account and Password
email = 'XXX'
pw = 'XXX'
# Login
def login(email, pw):
driver.get(
"https://sso.accounts.dowjones.com/signin")
time.sleep(5)
driver.find_element_by_xpath("//div/input[@name = 'username']").send_keys(email)
driver.find_element_by_xpath("//div/input[@name = 'password']").send_keys(pw)
driver.find_element_by_xpath("//div/button[@type = 'submit']").click()
login(email, pw)
time.sleep(30)
# Agree the Cookies Policy
driver.switch_to.frame("sp_message_iframe_490357")
driver.find_element_by_xpath("//button[@title='YES, I AGREE']").click()
time.sleep(5)
# Save Cookies
orcookies = driver.get_cookies()
print(orcookies)
cookies = {}
for item in orcookies:
cookies[item['name']] = item['value']
with open("wsjcookies.txt", "w") as f:
f.write(json.dumps(cookies))
|
Code II: Get Article List
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
import json
import requests
import csv
import unicodedata
from tqdm import tqdm
from random import randint
# Customize headers with keywords and current pagenum
def getheader(keywords, pagenum):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:88.0) Gecko/20100101 Firefox/88.0',
"content-type": "application/json; charset=UTF-8",
"Connection": "keep-alive",
"referrer": "https://www.wsj.com/search?query=%s&page=%s"%(keywords, pagenum)
}
return(headers)
# Customize parameters with keywords, startdate, and current page number
def getpara(keywords, startdate, pagenum):
para = "{\"query\":{\"not\":[{\"terms\":{\"key\":\"SectionType\",\"value\":[\"NewsPlus\"]}}],\
\"and\":[{\"full_text\":{\"value\":\"%s\",\
\"parameters\":[{\"property\":\"headline\",\"boost\":3},\
{\"property\":\"Keywords\",\"boost\":2},{\"property\":\"Body\",\"boost\":1}]}},\
{\"terms\":{\"key\":\"Product\",\"value\":[\"WSJ.com\",\"WSJ Blogs\",\"WSJ Video\",\
\"Interactive Media\",\"WSJ.com Site Search\",\"WSJPRO\"]}},\
{\"date\":{\"key\":\"UpdatedDate\",\"value\":\"%s\",\
\"operand\":\"GreaterEquals\"}}]},\"sort\":[{\"key\":\"liveDate\",\"order\":\"desc\"}],\
\"count\":20}/page=%s"%(keywords, startdate, pagenum)
return(para)
def searchlist(keywords, startdate, pagenum):
# Write cookies into RAM
with open("wsjcookies.txt", "r")as f:
cookies = f.read()
cookies = json.loads(cookies)
# Open a session
session = requests.session()
# Update search url with keywords, startdate, and current pagenum
url = "https://www.wsj.com/search?id=" \
+ requests.utils.quote(getpara(keywords, startdate, pagenum)) \
+ "&type=allesseh_search_full_v2"
# Load the opened session with parameters, headers, and cookies
# And Obtain json results from the server
data = session.get(url, headers=getheader(keywords, pagenum), cookies=cookies)
# Name the root json node of articles as 'info'
info = json.loads(data.text)['collection']
# Get the total page num
totalpage = int(json.loads(data.text)['data']['linksForPagination']['last'].split("=")[-1])
with open('reslist_%s.csv'%keywords, 'a') as g:
h = csv.writer(g)
# Write the id and type of each article into the opend csv file
for i in range(len(info)):
id = info[i]['id']
type = info[i]['type']
h.writerow([keywords, pagenum, id, type])
return(totalpage)
def searchwsj(keywords, startdate):
totalpage = searchlist(keywords, startdate, 0)
for page in tqdm(range(1, totalpage+1)):
searchlist(keywords, page)
if __name__ == "__main__":
searchwsj("twitter", "2009-06-30T00:00:00+00:00")
|
Code III: Get Article Info and Write Into Article List
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
import time
import json
import requests
import csv
from tqdm import tqdm
from lxml import etree
import pandas as pd
import unicodedata
from datetime import datetime
# Read the article ids from the article list obtained from last step
df = pd.read_csv("reslist_twitter.csv", header = None)
headers = {"User-Agent": "'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:88.0) Gecko/20100101 Firefox/88.0'",
"Accept": "*/*",
"Accept-Language": "en-US,en;q=0.5"
}
# A function dealing with the mismatching between ASCII and Unicode
def transuni(str):
str = unicodedata.normalize('NFD', str).encode('ascii', 'ignore').decode("utf-8")
return (str)
# A function transferring timestamp into date format
def transdate(stamp):
if stamp:
date = datetime.fromtimestamp(int(stamp)/1000).strftime("%Y-%m-%d %H:%M")
else:
date = "Invalid"
return(date)
def getarticle(id):
# Write cookies into RAM
with open("wsjcookies.txt", "r")as f:
cookies = f.read()
cookies = json.loads(cookies)
# Update url with article ID
url = "https://www.wsj.com/search?id="+id+"&type=article%7Ccapi"
# Open a session
session = requests.session()
# Load the session with headers and cookies
data = session.get(url, headers=headers, cookies=cookies)
# Name the root node as 'info'
info = json.loads(data.text)['data']
# Extract needed features
section = transuni(info['articleSection'])
byline = transuni(info['byline'])
headline = transuni(info['headline'])
printheadline = transuni(info['printedition_wsj_headline'])
summary = transuni(info['summary'])
href = info['url']
wordcount = info['wordCount']
createat = transdate(info['timestampCreatedAt'])
printat = transdate(info['timestampPrint'])
res = [section, byline, headline, printheadline, summary, href, wordcount, createat, printat]
return(res)
# Write article information and article id into csv file
with open('resref.csv', 'a') as g:
h = csv.writer(g)
headline = ['Keywords', 'PageNum', 'ArticleID', 'ArticleType', 'Section', 'Authors', 'Headline', \
'PrintedHeadline', 'Summary', 'Url', 'WordCount', 'CreatedAt', 'PrintedAt']
g.writerow(headline)
for line in tqdm(df.iterrows()):
if line[1][3] == "article|capi":
res = getarticle(line[1][2])
h.writerow(list(line[1])+res)
|
Code IV: Extract Article Contents
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import time
from lxml import etree
import csv
import re
from tqdm import tqdm
import requests
import json
import pandas as pd
import unicodedata
from string import punctuation
# Read the article id list
df = pd.read_csv("resref.csv",header=0)
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:88.0) Gecko/20100101 Firefox/88.0',
"content-type": "application/json; charset=UTF-8",
"Connection": "keep-alive"
}
# A function filtering unnecessary spaces and line break
def translist(infolist):
out = list(filter(lambda s: s and (type(s) != str or len(s.strip()) > 0),\ [i.strip() for i in infolist]))
return(out)
def parsearticle(title, date, articlelink):
# Obtain content of article page
with open("wsjcookies.txt", "r")as f:
cookies = f.read()
cookies = json.loads(cookies)
session = requests.session()
data = session.get(articlelink, headers=headers, cookies = cookies)
time.sleep(1)
page = etree.HTML(data.content)
# First record title and date into article content
arcontent = title + '\n\n' + date +'\n\n'
# Get article content
content = page.xpath("//div[@class='article-content ']//p")
for element in content:
subelement = etree.tostring(element).decode()
subpage = etree.HTML(subelement)
tree = subpage.xpath('//text()')
line = ''.join(translist(tree)).replace('\n','').replace('\t','').replace(' ','').strip()+'\n\n'
arcontent += line
return(arcontent)
for row in tqdm(df.iterrows()):
# Column Headline
title = row[1][6].replace('/','_')
# Column Url
articlelink = row[1][9]
# Column CreatedAt
date = row[1][11].split(" ")[0].replace('/','-')
# Write article content into the file named by its headline and date
arcontent = parsearticle(title, date, articlelink)
with open("%s_%s.txt"%(date,title),'w') as g:
g.write(''.join(arcontent))
|
Preview Results

Figure 6: Preview Article List
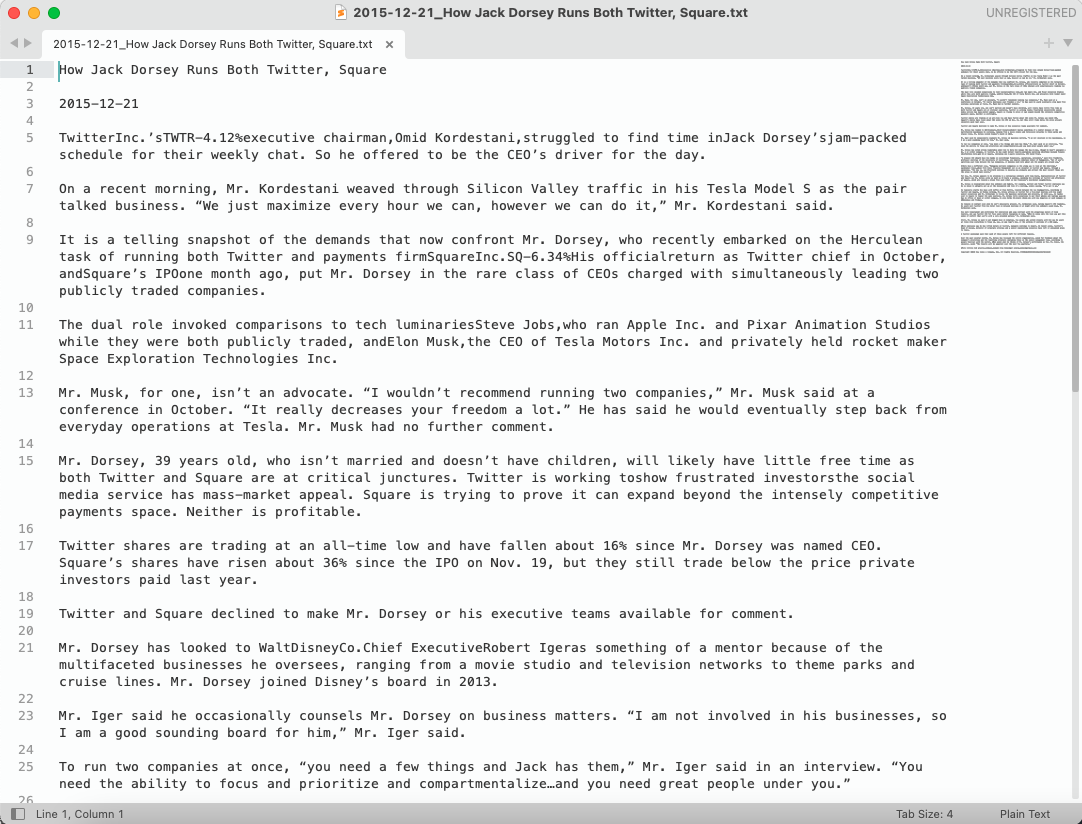
Figure 7: Preview Article Content
Reference
-
Zhu, Christina. 2019. “Big Data as a Governance Mechanism.” The Review of Financial Studies 32 (5): 2021–61.-PDF-.
-
Katona, Zsolt, Marcus Painter, Panos N. Patatoukas, and Jean Zeng. 2018. “On the Capital Market Consequences of Alternative Data: Evidence from Outer Space.” SSRN Scholarly Paper ID 3222741. Rochester, NY: Social Science Research Network. -PDF-.
-
Mukherjee, Abhiroop, George Panayotov, and Janghoon Shon. 2021. “Eye in the Sky: Private Satellites and Government Macro Data.” Journal of Financial Economics, March. -PDF-.