Motivation
Just like the trading imbalance could be a powerful signal for upcoming stock price movement, investors’ information acquisition actions are also indicative for future security returns. According to Lee and So (2015), acquiring information is costly for investors and thus they only do so when the expected profits can cover the relative costs. Ceteris paribus, securities which attract more investor attention may have a higher likelihood of experiencing abnormal stock volatility from which a sophisticated investor can cultivate Alphas.
The information content of investors’ information acquisition actions has been well validated by a series of papers. For example, Da, Engelberg, and Gao (2011, JF) utilize search frequency in Google (Search Volume Index (SVI)) as a proxy for investor attention and show that firms with abnormally bigger Google search volume are more likely to have a higher stock price in the next 2 weeks and an eventual price reversal within the year, suggesting that the Google search volume may mainly capture the less sophisticated retail investors’ attention. Similarly, Drake, Johnson, Roulstone, and Thornock (2020, TAR) find that downloads number of a firm’s company filings filed in the EDGAR is significantly predictive of its subsequent performance and the predictive power is mainly driven by downloads from institutional investors’ IP address.
Employing news searching and news reading intensity for specific stocks on Bloomberg terminals as a new proxy for institutional investor attention, Ben-Rephael, Da, Israelsen (2017, RFS) and Easton, Ben-Repahael, Da, Israelsen (2021, TAR) more explicitly illustrated the lead-lag relationship between retail attention and institutional attention, suggesting that institutional investors are typically aware of the material firm-specific information earlier than retail investors and tend to make use of their information advantage by opportunistically providing liquidity when price pressure induced by retail investors arrives.
The take away from the literature is that by observing different market participants’ information acquisition actions in time-series, one can not only trace back how the current stock price was previously formulated, but also gain insights about how the stock price will evolve in the future.
The idea that predicting the stock movement from current market participants’ information acquisition actions, in my opinion, is especially fascinating: even though you have no idea about what exactly has happened to a specific firm, you could still get sense that there must be something abnormal when observing some unsual information acquisition actions targeted toward this firm in the market. From this perspective, approachable records of market participants’ information acquisition actions per se may facilitate the implicit dissemination of non-public material information in the market.
Take the stylized facts documented by Easton, Ben-Repahael, Da, Israelsen (2021, TAR) as an example. Figure 1 shows that when something material happens and a firm is obliged to file a 8-K to the SEC, one can always get informed days earlier than the publication of the 8-K filing by observing the abnormal Bloomberg Read Heat, depsite that he/she has no idea about what exactly has happened to the firm. Given the significant price pressure after the publication of 8-Ks, the information advantage means (potentially huge) trading profits.
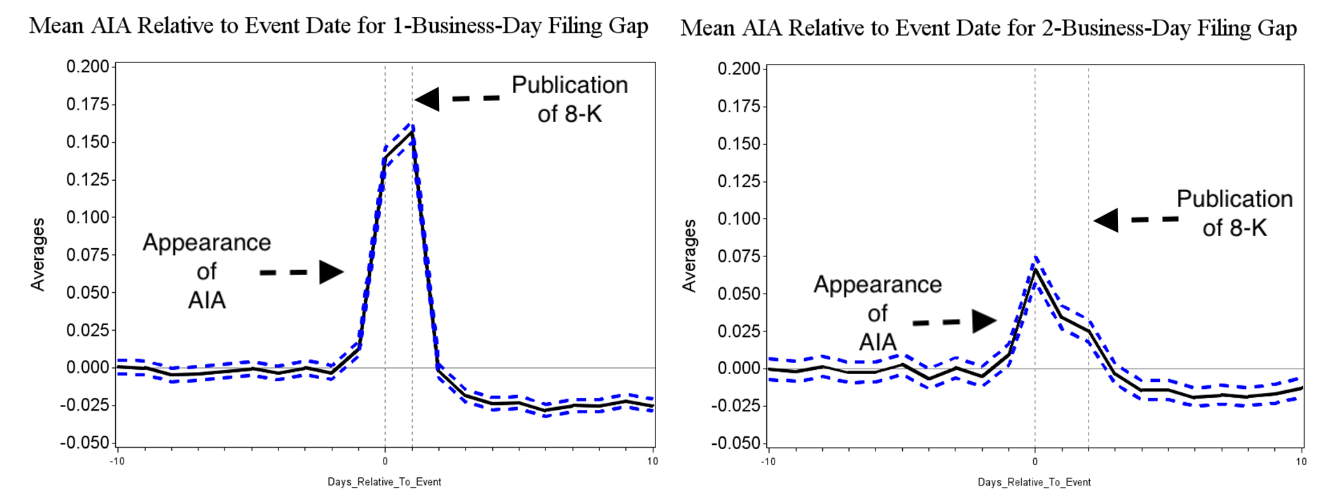
In this blog, I will introduce how to collect data and formulate the weekly measure for retail/institutional information acquisition actions. In particular, following Ben-Rephael, Da, Israelsen (2017, RFS) and Easton, Ben-Repahael, Da, Israelsen (2021, TAR), I will use Google Search Volume Index (SVI) to capture retail attention and Bloomberg institutional investors’ read heat to capture institutional information acquisition actions.
Formulate Retail Information Acquisition Measure (SVI)
As far as I know, the Google Search Volume Index (SVI) started to be recognized as a reasonable proxy for retail investors’ attention/information acquisition intensity in accounting and finance literature after the publication of Da, Engelberg, and Gao (2011, JF). The idea is that while institutional investors have more advanced platforms to gather information (e.g., Bloomberg, Reuters, etc), the majority of retail investors have to count on the Google search engine for information acquisition. Actually, the authors did find “a strong and direct link” between Google Search Volume Index (SVI) and retail order execution.
Following Da, Engelberg, and Gao (2011, JF), I will collect the weekly Google Search Volume Index (SVI) for each stock symbol, which could be then used for calculating the abnormal retail attention ASVI by substracting the rolling-average in the past 8 weeks from the current-week Google Search Volume Index (SVI).
Analyse Google Trends Website
Manual Search
Firstly, let’s randomly post two stock symbols and a date range and analyze how Google Trends API reacts to our post. Here I use tickers of Apple and Amazon, AAPL and AMZN, as search keywords. The date range is randomly specified as “2021-08-08 2022-08-08”.
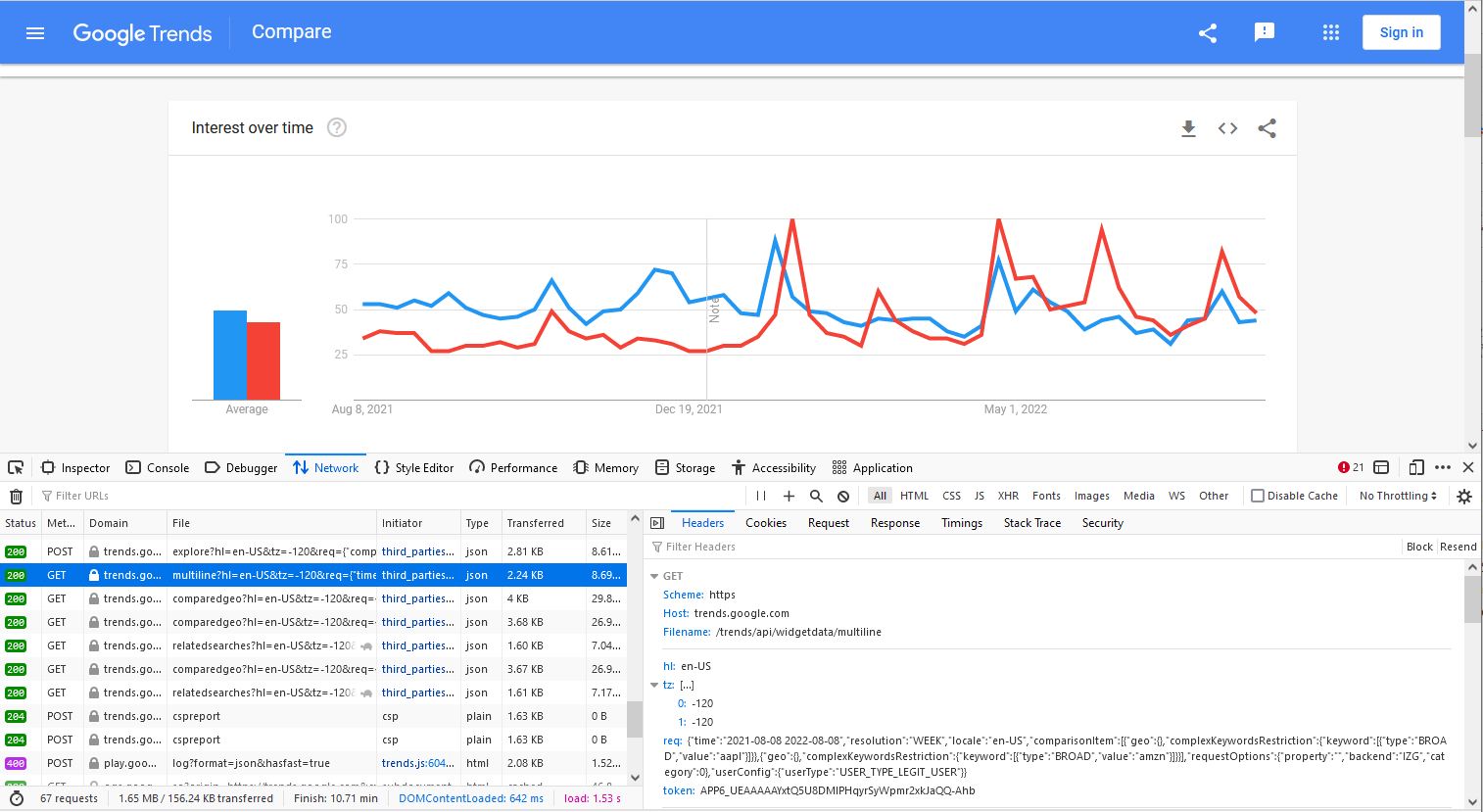
Figure 2 shows that the time series of the Search Volume Index is returned with json format and should contain ingredients when requesting as follows. In addition, one can also easily find out the cookies in the rendering results of the same reuqest.
Request method: GET
Base url: https://trends.google.com/trends/api/widgetdata/multiline
Request parameters:
|
|
By fetching the response message of the rendered url in the web browser, we can figure out the headers and the exact request url.
|
|
After the simple decoding of the request url, one can find out the request url is exactly the combination of the base url and specified parameters.
|
|
Analyze Parameter Structure
A typical set of post parameters is as follows.
|
|
My little experiment shows that there are in general three components of the parameters.
-
Relatively Fixed Part
- The parameter
hlspecifies host language for accessing Google Trends, by defaulten-US - The parameter
tzspecifies time zone offset (in minutes). For example360means UTC -6 which is US CST
- The parameter
-
Variable Core Part
-
The parameter
reqconsists of the following sub-parameters-
time: time frame for search, in our sample case is2021-08-08 2022-08-08 -
resolution: frequency of returned time series, in our sample case isWEEK, could also beHOUR,DAYorMONTH. There are different limitations for the span of the date range under different resolution levels. -
locale:en-US, same ashl -
comparisonItem: information about the search keywords, each keyword has a parallel complete post structure with following format
1{"geo":{},"complexKeywordsRestriction":{"keyword":[{"type":"BROAD","value":"aapl"}]}}-
requestOptions: typically fixed{"property":"","backend":"IZG","category":0} -
userConfig:{"userType":"USER_TYPE_LEGIT_USER"}. Might be different if you post those parameters using algorithms. I will elaborate the details later.
-
-
The parameter
tokenis the password for configuration from Google. This encrypted parameter needs another request. I will elaborate the details later.1token: APP6_UEAAAAAYxtQ5U8DMlPHqyrSyWpmr2xkJaQQ-Ahb
-
In sum, we can fill most parameters with the information we have in hand, such as the keyword list [‘AAPL’, ‘AMZN’] and the search range 2021-08-08 2022-08-08. The only obstacle left is that we have no idea how does Google encrypts those parameters and generate the dynamic secrets token.
Don’t worry. I will show how to get access to those encrypted tokens in the next subsection.
Find Out Tokens
With more checks on the page source, I find that the tokens are also returned with the format of json and can be accessed by posting the basic searching parameters to another url https://trends.google.com/trends/api/explore.
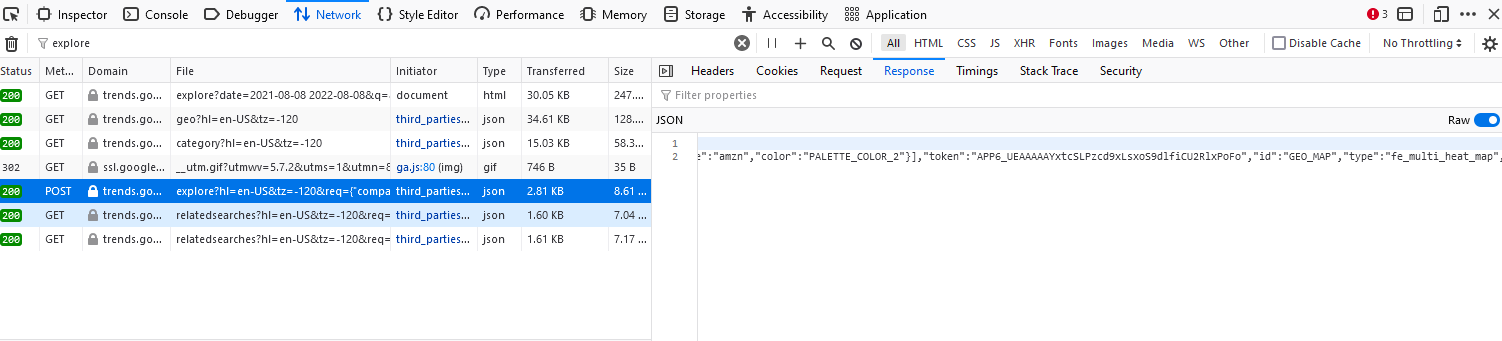
With the similar procedures as those in the previous subsection. I find the parameter structure for this request is as follows.
|
|
Apparently, there is no information that is beyond our information set in this set of parameters.
The compressed returned json is as follows, from which one can easily find out the tokens and all the other parameters in need. Note that in addition to the time series of Google Search Index, this request also returns tokens for other type of information, such as data of geographical distributionGEO_MAP and keyword lists that are typically searched together with the focal keywordRELATED_QUERIES. Here I only display returned information, especially the token, for time series of Google Search Index.
Simply compare the following returned json in this subsection and the request parameters for the extracting of the time series data in the previous subsection, one will find that all the core variable parameters, req and token, needed in the previous subsection are contained in the following returned json.
|
|
Algorithm
For now, we have figured out all the necessary ingredients for writing the algorithm of automating the downloads of Google Search Volume Index (SVI).
Step 0: Define global variables that will be repeatedly used.
Step 1: Post the search keywords as well as the date range to https://trends.google.com/trends/api/explore and get the tokens as well as the parameters for the next step.
Step 2: Use the parameters obtained in Step 1 to obtain the time series Google Search Volume Index from https://trends.google.com/trends/api/widgetdata/multiline
Step 3: Clean the raw time series data and write it into the file.
Step 0: Define global variables
|
|
Step 1: Get Tokens
Input:
kw_list: keyword list, must be lower case, at maximum 5, e.g.,['appl', 'amzn']daterange: search range, with format like2021-08-08 2022-08-08
|
|
In case one also want to obtain other type of information such as the geographical distribution of the Google search, I recorded all the returned tokens and parameters in this step.
The output of this step reqparas contains necessary parameters request and token for the request of time series Search Volume Index.
|
|
Step 2: Request Time Series of Search Volume Index
The input keyword list and date range is exactly the same as in Step 1. Parameter req and token are both inherited from the output of the Step 1 reqparas.
|
|
The output is json-formatted time series of Search Volume Index. The typical format is as following.
|
|
Step 3: Clean and Save Data
The input conatins
req_json: Json-formatted time series, output of Step 2savefile: File to store the returned results, e.g., “GTRES_20220908.csv”kw_list: List of search keywords. Properties are the same as in Step 1.
|
|
The raw dataframe structure is as following.
| time | formattedTime | formattedAxisTime | value | hasData | formattedValue |
|---|---|---|---|---|---|
| 1399161600 | May 4 - 10, 2014 | 4-May-14 | [96, 5, 0] | [True, True, False] | [‘96’, ‘5’, ‘0’] |
| 1399766400 | May 11 - 17, 2014 | 11-May-14 | [80, 6, 4] | [True, True, True] | [‘80’, ‘6’, ‘4’] |
| 1400371200 | May 18 - 24, 2014 | 18-May-14 | [97, 6, 3] | [True, True, True] | [‘97’, ‘6’, ‘3’] |
| 1400976000 | May 25 - 31, 2014 | 25-May-14 | [86, 6, 5] | [True, True, True] | [‘86’, ‘6’, ‘5’] |
| 1401580800 | Jun 1 - 7, 2014 | 1-Jun-14 | [82, 5, 3] | [True, True, True] | [‘82’, ‘5’, ‘3’] |
| 1402185600 | Jun 8 - 14, 2014 | 8-Jun-14 | [76, 8, 5] | [True, True, True] | [‘76’, ‘8’, ‘5’] |
| 1402790400 | Jun 15 - 21, 2014 | 15-Jun-14 | [87, 6, 2] | [True, True, True] | [‘87’, ‘6’, ‘2’] |
| 1403395200 | Jun 22 - 28, 2014 | 22-Jun-14 | [74, 3, 2] | [True, True, True] | [‘74’, ‘3’, ‘2’] |
| 1404000000 | Jun 29 - Jul 5, 2014 | 29-Jun-14 | [74, 0, 0] | [True, False, False] | [‘74’, ‘0’, ‘0’] |
| 1404604800 | Jul 6 - 12, 2014 | 6-Jul-14 | [84, 3, 2] | [True, True, True] | [‘84’, ‘3’, ‘2’] |
| 1405209600 | Jul 13 - 19, 2014 | 13-Jul-14 | [71, 5, 2] | [True, True, True] | [‘71’, ‘5’, ‘2’] |
To make sure the columns are comparable among different requests, the formatted and saved dataframe structure has a panel-data format.
| Date | Symbol | SVI |
|---|---|---|
| 5/4/2014 | DRIV | 96 |
| 5/4/2014 | DRNA | 5 |
| 5/4/2014 | DRQ | 0 |
| 5/4/2014 | DRRX | 1 |
| 5/11/2014 | DRII | 5 |
| 5/11/2014 | DRIV | 80 |
| 5/11/2014 | DRNA | 6 |
| 5/11/2014 | DRQ | 4 |
| 5/11/2014 | DRRX | 2 |
| 5/18/2014 | DRII | 2 |
| 5/18/2014 | DRIV | 97 |
| 5/18/2014 | DRNA | 6 |
| 5/18/2014 | DRQ | 3 |
| 5/18/2014 | DRRX | 4 |
| 5/25/2014 | DRII | 0 |
| 5/25/2014 | DRIV | 86 |
| 5/25/2014 | DRNA | 6 |
| 5/25/2014 | DRQ | 5 |
| 5/25/2014 | DRRX | 2 |
Collect Raw SVI
|
|
Formulate Institutional Information Acquisition Measure (AIA)
Bloomberg as the Data Source
To my knowledge, Ben-Rephael, Da, Israelsen (2017, RFS) was the first to use the Bloomberg Read Heat (AIA) was firstly as a proxy for institutional attention. According to their paper, Bloomberg records the number of times news articles on a particular stock are read by its terminal users and the number of times users actively search for news about a specific stock. … They assign a score of 0 if the rolling average is in the lowest 80% of the hourly counts over the previous 30 days. Similarly, Bloomberg assigns a score of 1, 2, 3 or 4 if the average is between 80% and 90%, 90% and 94%, 94% and 96%, or greater than 96% of the previous 30 days’ hourly counts, respectively. … Bloomberg aggregates up to the daily frequency by taking a maximum of all hourly scores throughout the calendar day.
Collect Bloomberg News Read Heat
In my previously blog Extract Mass Data Via Bloomberg API, I have displayed how to obtain a specific variable from Bloomberg via Bloomberg API. In this case, the variable of interest NEWS_HEAT_READ_DMAX. Maybe you also want to obtain some related variables like the number of news per day and the tone of the news, etc.
Then just request them from the Bloomberg.
|
|
Summary
In this blog, I showed the value of investors’ attention (or information acquisition actions) and introduced how to collect data for the purpose of formulating the proxies of retail attention and institutional attention respectively. Following Ben-Rephael, Da, Israelsen (2017, RFS) and Ben-Repahael, Da, Israelsen (2021, TAR) , I use Google Search Volume Index (SVI) to capture retail attention and news reading intensity for specific stocks on Bloomberg terminals as a new proxy for institutional investor attention.
References
Ben-Rephael, Azi, Zhi Da, and Ryan D. Israelsen. “It depends on where you search: Institutional investor attention and underreaction to news.” The Review of Financial Studies 30, no. 9 (2017): 3009-3047.
Da, Zhi, Joseph Engelberg, and Pengjie Gao. “In search of attention.” The Journal of Finance 66, no. 5 (2011): 1461-1499.
Drake, Michael S., Bret A. Johnson, Darren T. Roulstone, and Jacob R. Thornock. “Is there information content in information acquisition?.” The Accounting Review 95, no. 2 (2020): 113-139.
Lee, Charles MC, and Eric C. So. “Alphanomics: The informational underpinnings of market efficiency.” Foundations and Trends® in Accounting 9.2–3 (2015): 59-258.
Peter Easton, Azi Ben-Repahael, Zhi Da, Ryan Israelsen. “Who Pays Attention to SEC Form 8-K?.” The Accounting Review (2021)